
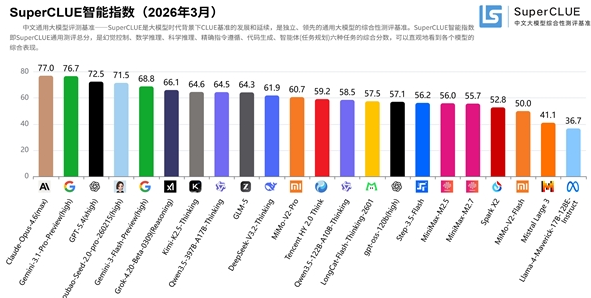
SuperCLUE正式发布了“2025年度中文大模型基准测评报告”,这场汇聚了23个国内外顶尖模型的“全明星赛”,再次揭示了全球AI战局的新动向。测评覆盖了数学推理、代码生成及科学推理等六大核心维度,直观展示了当前中文语境下各大模型的真实“战力”。

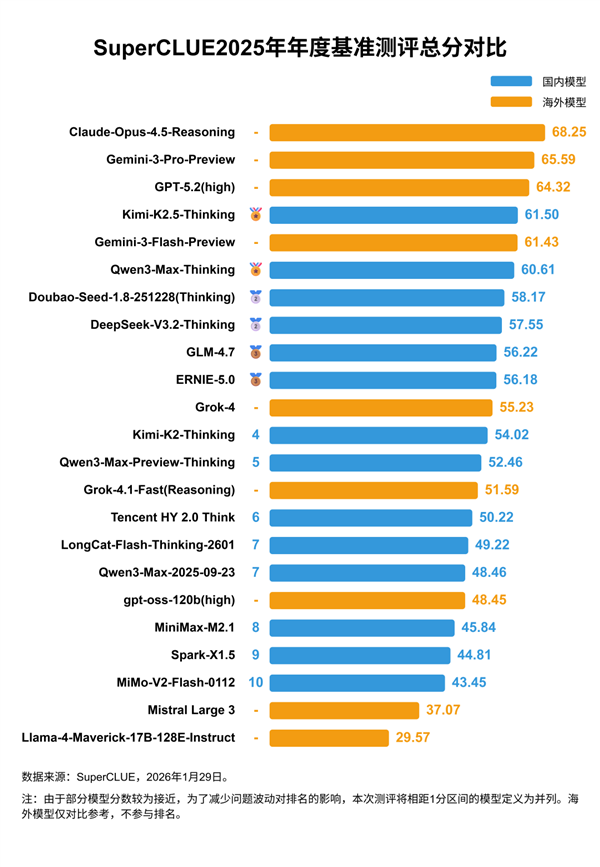
从综合排名来看,海外闭源模型依然展现出强大的统治力。Anthropic旗下的Claude-Opus-4.5-Reasoning凭借68.25的高分问鼎榜首,谷歌的Gemini-3-Pro-Preview与OpenAI的GPT-5.2(high)紧随其后,分别夺得亚军和季军。这三大巨头构成的“第一梯队”,在逻辑严密性和综合理解力上依然保持着微弱的领先优势。
然而,国产大模型的表现堪称惊喜,正以前所未有的速度缩小差距。国内开源界的“领头羊”Kimi-K2.5-Thinking与闭源代表Qwen3-Max-Thinking分别杀入全球前十,位列第四和第六。值得振奋的是,在垂直赛道上,国产模型已经实现了“局部反超”:Kimi在代码生成任务中勇夺全球第一,而Qwen3则在数学推理上与谷歌并列世界冠军。
纵观整体格局,海内外呈现出截然不同的竞争态势。闭源领域目前是“海外领跑、国产追赶”;而在开源领域,国产模型则占据了绝对的主导地位,国内开源Top5的实力已大幅领先海外同类模型。这种“开闭并进”的局面,预示着中文AI生态正进入一个高质量发展的爆发期。
划重点:
🏆 海外巨头领跑: Claude-Opus-4.5-Reasoning以最高分位居全球中文大模型战力榜首,海外闭源模型依然包揽前三名。
🚀 国产局部超越: Kimi-K2.5-Thinking在代码生成领域夺冠,Qwen3-Max-Thinking则在数学推理上与谷歌Gemini并列全球第一。
📊 开源国产主导: 在开源模型阵营中,国产模型表现远超海外竞争对手,展现了国内大模型生态在开放协作方面的独特优势。

960x540.jpg)
发评论,每天都得现金奖励!超多礼品等你来拿
登录 在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则