内容持续更新中
据报道,OpenAI前研究员田永龙已于近期加入腾讯,预计将出任混元多模态模型方向的负责人,后续参与视觉语言模型的研发工作。若这笔人事变动最终落定,这将是继姚顺雨之后,又一位从OpenAI核心研究团队转…
全球开源大模型生态迎来架构层面的颠覆性突破。谷歌于6月3日正式发布了全新统一多模态模型Gemma412B。该模型最大的创新在于彻底取消了传统多模态模型必不可少的“编码器”组件,在消费级硬件的本地部署与…
近日,谷歌正式发布了其最新的统一多模态模型 ——Gemma 4 12B。这款模型具有 12 亿个参数,最大的亮点在于它不需要传统的多模态编码器,能够直接处理视觉和音频数据。为了适应消费级硬件的使用需求…
近日,网易有道宣布“子曰”大模型迎来4.0版本的全方位升级。“子曰4" 正式迈入全模态时代,不仅全面支持文本、图片、音频的融合交互,有道更宣布将核心的“多模态模型”与“语音合成(TTS)模型…
通用人工智能实验室 MiniMax(稀宇科技)近日正式宣布启动一项名为「10x Team」的全球人才合作计划。该计划的核心目标是寻找并汇聚各行业的顶尖专家,共同探索大模型在特定垂直领域的深度应用。Mi…
MiniMax(稀宇科技)于2026年3月23日宣布将其原有的Coding Plan全面升级为“Token Plan”,推出全球首个支持全模态模型的订阅计划。此次升级标志着MiniMax从单一编程提效…
近日,据《科创板日报》消息,国内大模型领先企业月之暗面计划在2026年第一季度(拟定于1月或3月)上线全新的多模态模型。据悉,该模型型号或定名为K2.1/K2.5,将在多模态处理与智能体(…
在刚刚结束的智谱多模态开源周中,智谱团队宣布开源四项针对视频生成的核心技术。这些技术不仅展示了智谱在多模态模型领域的最新进展,也为视频生成的未来发展奠定了坚实基础。 在过去一周内,智谱 GLM 团队先…
在近期举办的 Axios AI + 峰会上,谷歌 DeepMind 的首席执行官德米斯・哈萨比斯(Demis Hassabis)分享了他对未来一年 AI 领域的展望。他指出,2026 年将是多模态模型…
法国人工智能初创公司 Mistral 于周二发布了一系列新模型,旨在追赶全球领先的 AI 实验室如谷歌、OpenAI 和 DeepSeek。此次发布紧随 DeepSeek 和谷歌近期的模型更新,显示出…
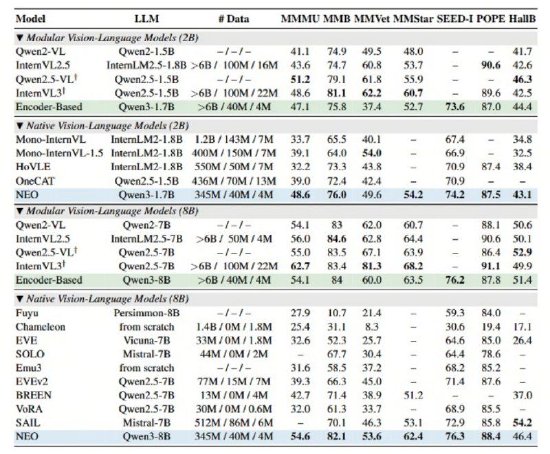
商汤科技与南洋理工大学S-Lab联合发布并开源全新多模态模型架构NEO,通过底层架构创新实现视觉与语言的深层统一,在性能、效率和通用性上取得全面突破。 极致数据效率:1/10数据量达顶尖性能 NEO最…
快手近日正式发布其新一代旗舰多模态模型 Keye-VL-671B-A37B,并同步开放代码。这一模型以其 “善看会想” 的特性,在通用视觉理解、视频分析和数学推理等多项核心 benchmark 中表现…
谷歌发布Gemini 3后,其中Gemini 3 Pro以1501 Elo刷新LMArena公开榜单历史最高分,超越GPT-5.1、Claude 4. 5 与Grok-4.1,成为目前评分最高的多模态…
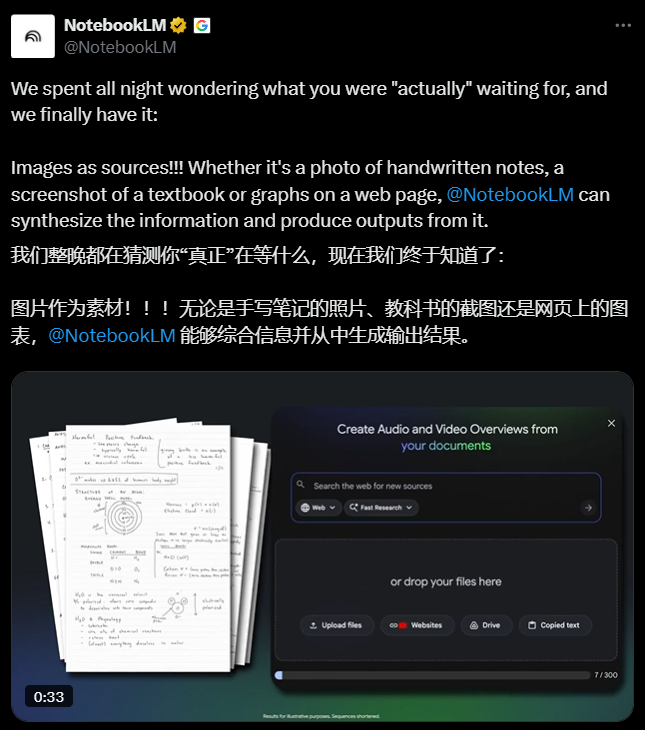
谷歌宣布NotebookLM新增图像数据源,用户上传黑板板书、教科书扫描页或街拍表格后,系统自动完成OCR与语义解析,并可用自然语言直接检索图中内容。该功能面向全平台免费推出,谷歌表示未来数周内将追加…
过去两年,人工智能的浪潮席卷全球,从 ChatGPT 的自然语言革命,到多模态模型可以自动生成图像、视频、音频的时代。 每一个企业、每一位开发者,都在尝试让 AI 成为生产力的一部分。 然而,在实际落…
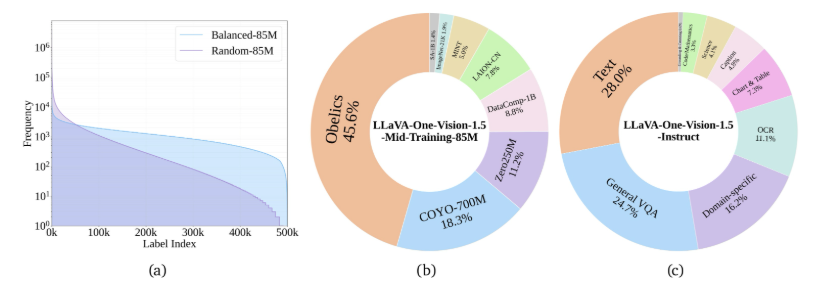
近日,开源社区迎来了 LLaVA-OneVision-1.5,这是一款全新的多模态模型,标志着技术的一次重大进步。LLaVA(大型语言与视觉助手)系列历经两年开发,逐步从简单的图文对齐模型演变为能够处…
在全球科技界备受瞩目的国际计算机视觉大会(ICCV)即将于2025年10月19日至23日在美丽的檀香山召开,苹果公司确认将携带多项重要研究成果亮相这一盛会。此次大会旨在聚焦计算机视觉领域的前沿技术和研…
近日,该公司宣布成立 “机器人和具身 AI 小组”,标志着其在智能领域的进一步拓展。这一新团队由阿里巴巴高管林俊旸负责,他同时也是公司旗舰 AI 基础模型 “通义千问” 的技术负责人。 林俊旸在社交媒…
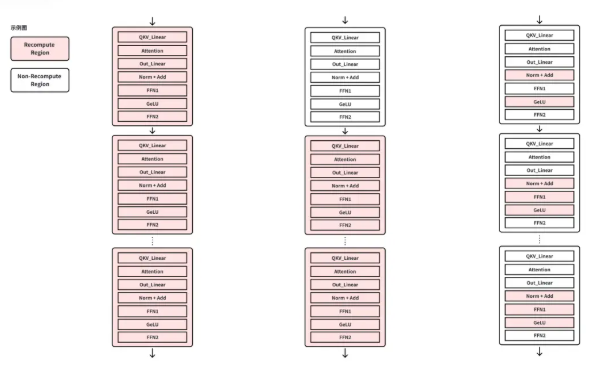
近日,字节跳动宣布开源其内部开发的 VeOmni 框架,这是一款专注于多模态模型训练的统一框架。随着人工智能技术的不断发展,特别是从单一语言模型向文本、图像和视频的多模态演进,算法工程师们在训练过程中…
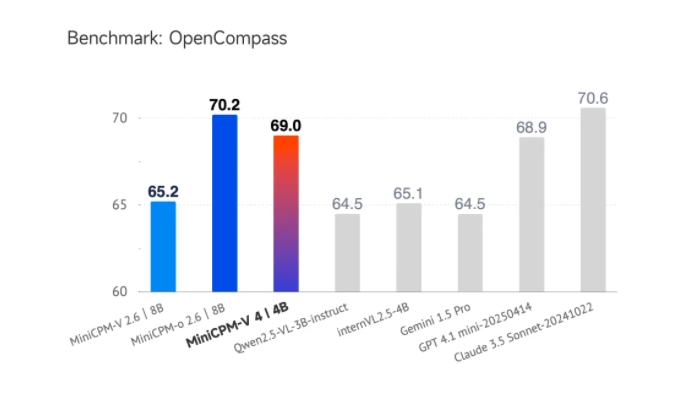
魔搭ModelScope社区宣布,面壁小钢炮新一代多模态模型MiniCPM-V4.0正式开源。凭借4B参数量,该模型在OpenCompass、OCRBench、MathVista等多个榜单…
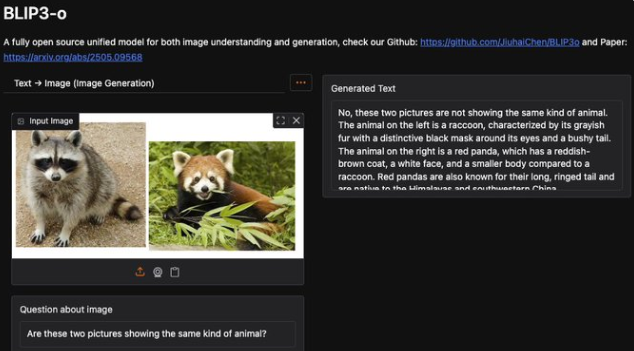
Salesforce AI Research在Hugging Face平台正式发布BLIP3-o应用,这款全开源的统一多模态模型家族以其卓越的图像理解与生成能力引发业界热议。BLIP3-o通过创新的扩…
2025年4月26日 AIbase报道:OpenAI近日宣布,其旗舰多模态模型GPT-4o的图像生成功能现已正式集成至ChatGPT的自定义GPTs功能中。这一更新标志着用户创建的定制化AI助手能够直…
字节跳动宣布推出全新多模态模型Vidi,专注于视频理解与编辑,首版核心能力为精准的时间检索功能。据AIbase了解,Vidi能够处理视觉、音频和文本输入,支持长达一小时的超长视频分析,在时间检索任务上…
在今天凌晨1点的技术直播中,OpenAI正式推出其最新且最强大的多模态模型o4-mini和满血版o3。这两款模型具备独特优势,不仅能同时处理文本、图像和音频,还可作为智能体自动调用网络搜索、图像生成、…
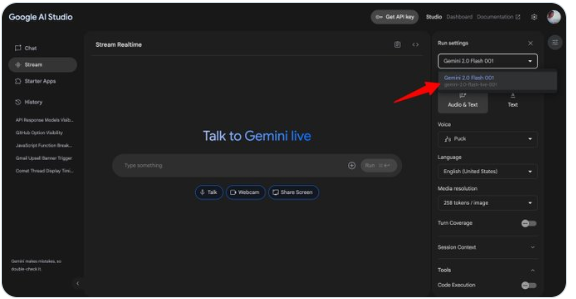
近日,谷歌人工智能开发平台Google AI Studio迎来了一次重大更新,全新的“Gemini-2.0-flash-live-001”模型正式亮相,并即刻取代了此前处于实验阶段的Gemini2.0…
在人工智能领域,阿里巴巴近日公布了一则引人瞩目的消息:他们开源了最新的多模态模型——Qwen2.5-VL-32B-Instruct。作为Qwen2.5系列的新成员,这款32B版本的模型在维持高性能的同…
在人工智能领域,阿里通义实验室团队近日宣布开源其最新研发的多模态模型 ——R1-Omni。这一模型结合了强化学习与可验证奖励(RLVR)方法,展现出了在处理音频和视频信息方面的卓越能力。R1-Omni…
全球开发者目光再次聚焦中国!在备受瞩目的全球开发者大会(GDC)上,阿里云魔搭社区重磅宣布,首发上线阶跃星辰最新开源的两款多模态模型,包括 全球参数量最大的开源视频生成模型 Step-Vid…
(696x696).jpg)




960x540.jpg)