
大语言模型
205篇
内容持续更新中

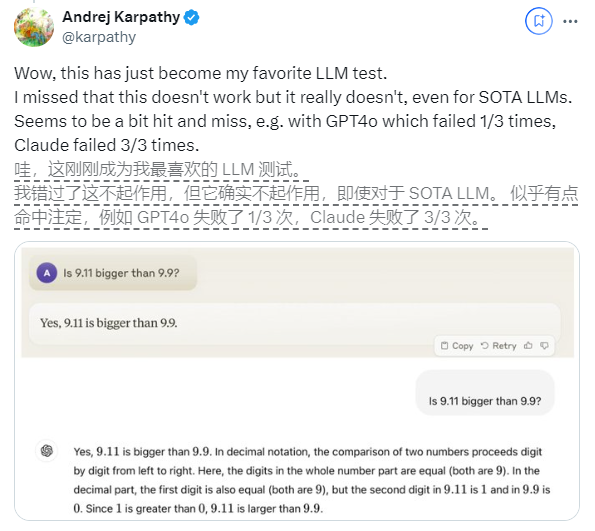

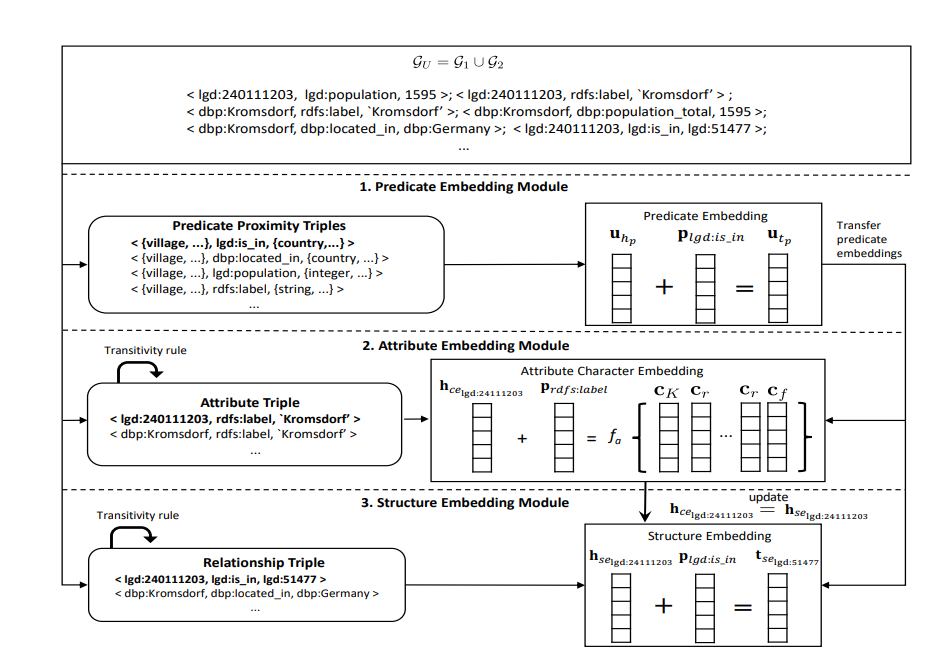





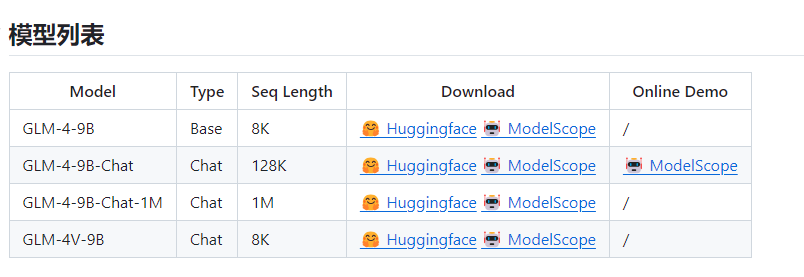
阅读量飙升 微软6页论文爆火:三进制LLM,真香!
大语言模型迎来了“1-bit时代”,微软和中国科学院大学提出的BitNet b1.58方法将参数转换成三进制表示,从根本上减少了模型的内存占用和简化了计算过程。该方法在不同大小的模型上进行了性能比较,…
新鲜出炉,等待你的评论
暂无评论,快留下你的脚印吧!还可以领现金哦~
内容持续更新中
大语言模型迎来了“1-bit时代”,微软和中国科学院大学提出的BitNet b1.58方法将参数转换成三进制表示,从根本上减少了模型的内存占用和简化了计算过程。该方法在不同大小的模型上进行了性能比较,…


