内容持续更新中
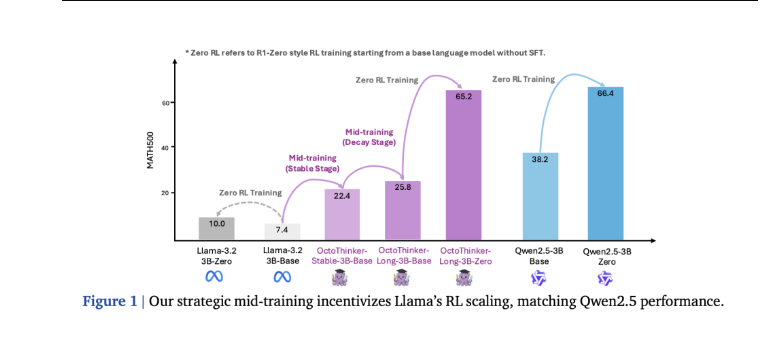
大型语言模型(LLM)通过结合任务提示和大规模强化学习(RL)在复杂推理任务中取得了显著进展,如 Deepseek-R1-Zero 等模型直接将强化学习应用于基础模型,展现出强大的推理能力。然而,这种…