内容持续更新中
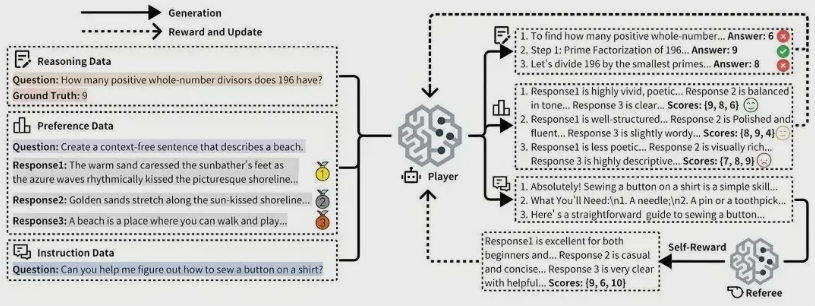
近日,摩尔线程的 AI 研究团队在国际顶级学术会议 AAAI2026上发布了其最新研究成果,提出了一种名为 URPO(统一奖励与策略优化)的创新框架。这项技术旨在简化大语言模型的训练过程,并突破其性能…