
近日,月之暗面发布了一种全新的混合线性注意力架构,名为 “Kimi Linear”。这一架构据称在处理短距离、长距离信息以及强化学习(RL)等多种场景中,性能优于传统的全注意力方法。其核心技术 Kimi Delta Attention(KDA)是对 Gated DeltaNet 的一次优化,特别引入了一种更高效的门控机制,以更好地管理有限状态 RNN 的记忆使用。

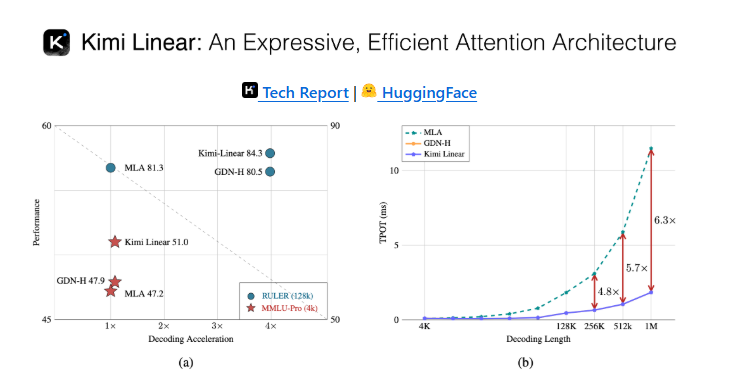
Kimi Linear 的设计由三份 Kimi Delta Attention 和一份全局 MLA 组成。这种结构通过细粒度的门控来压缩有限状态 RNN 的记忆,使得模型在处理信息时更加高效。官方指出,在处理1M token 的数据场景中,Kimi Linear 的 KV cache 占用降低了75%,而解码吞吐量最高可提升6倍,TPOT 相较于传统 MLA 加速了6.3倍。
这种新的架构为各种 AI 应用场景提供了更强的支持,无论是在信息密集型的自然语言处理任务还是在动态环境中的强化学习,Kimi Linear 都有着显著的优势。随着 AI 技术的不断发展,这种高效的注意力机制可能会为未来的智能应用带来新的突破。
更多技术细节可以在 Kimi Linear 的技术报告中找到,https://github.com/MoonshotAI/Kimi-Linear/blob/master/tech_report.pdf。
划重点:
🌟 Kimi Linear 是一种新型的混合线性注意力架构,优化了信息处理性能。
🚀 该架构在1M token 场景下,KV cache 占用减少75%,解码吞吐量提升6倍。
🔍 Kimi Delta Attention 是其核心技术,通过细粒度门控优化了 RNN 的记忆管理。


发评论,每天都得现金奖励!超多礼品等你来拿
登录 在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则