
Google DeepMind 近日正式发布 Gemini3.1Flash-Lite 预览版,标志着 Gemini3系列中速度最快、性价比最高的成员面世。作为 Gemini2.5Flash-Lite 的迭代产品,新模型在保持每秒超360个 token 的极速输出及5.1秒平均响应时间的基础上,实现了智能水平的显著跨越。根据 Artificial Analysis 智能指数监测,该模型得分较前代提升12分至34分,并在 Arena.ai 排行榜中凭借1432的 Elo 分数展现出强劲的人类偏好竞争力。
")
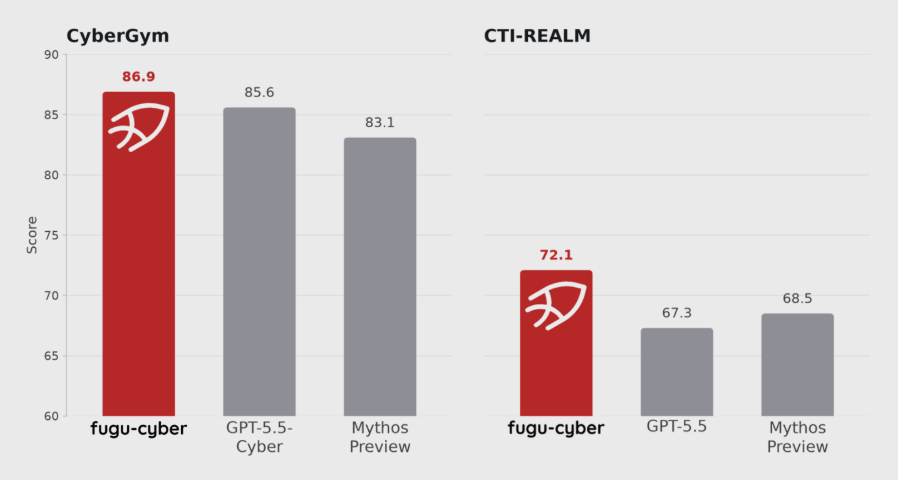
在多模态与科学推理等核心维度,Gemini3.1Flash-Lite 的表现尤为突出,其在 GPQA Diamond 测试中取得86.9% 的高分,MMMU-Pro 基准测试准确率达76.8%,性能已超越 Claude Opus4.6与 Kimi K2.5等重型模型。值得注意的是,该模型支持开发者自定义“思考”深度,使其能够灵活适配从简单的自动化翻译到复杂的 UI 构建等多样化场景。

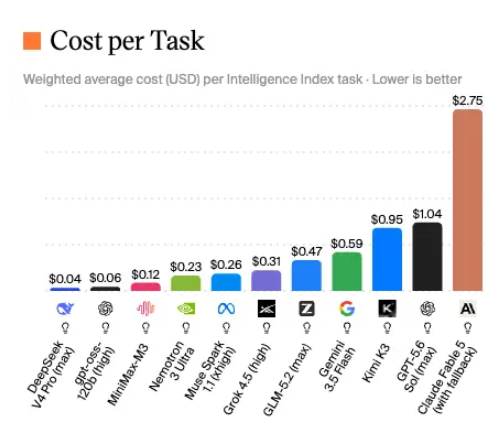
然而,性能与速度的双重进化伴随着显著的成本调整。Gemini3.1Flash-Lite 的每百万输入 token 价格上调至0.25美元,输出价格则由前代的0.40美元大幅升至1.50美元,涨幅接近三倍。
这一价格策略反映了当前模型厂商在追求极速推理与高精度逻辑平衡时的成本压力。随着该模型在 Google AI Studio 及 Vertex AI 开放测试,轻量化模型市场正从单纯的“低价竞争”转向“高性能逻辑下放”的新阶段。

(696x696).jpg)
发评论,每天都得现金奖励!超多礼品等你来拿
登录 在评论区留言并审核通过后,即可获得现金奖励,奖励规则可见: 查看奖励规则