紫东太初多模态大模型
“紫东太初”跨模态通用人工智能平台是由中国科学院自动化研究所研发的以多模态大模型为核心、基于全栈国产化基础软硬件平台,可支撑全场景AI应用。依托面向超大规模的高效分布式训练框架,自动化所构建了具有业界领先性能的中文预训练模型、语音预训练模型、视觉预训练模型,并开拓性地通过跨模态语义关联实现了视觉-文本-语音三模态统一表示,构建了三模态预训练大模型,赋予跨模态通用人工智能平台多种核心能力。
“紫东太初”兼具跨模态理解和生成能力,具有了在无监督情况下多任务联合学习、并快速迁移到不同领域数据的强大能力。对更广泛、更多样的下游任务提供模型基础支撑,达成AI在如视频配音、语音播报、标题摘要、海报创作等更多元场景的应用。
特色:
- 全球首个多模态图文音预训练模型
- 多层次多任务自监督学习
- 弱关联多模态数据语义统一表达
- 兼顾任务感知和推理增强的中文预训练模型
- 多粒度学习与注意力指导的视觉预训练模型
- 基于自监督预训练的多任务语音建模技术
中文预训练模型
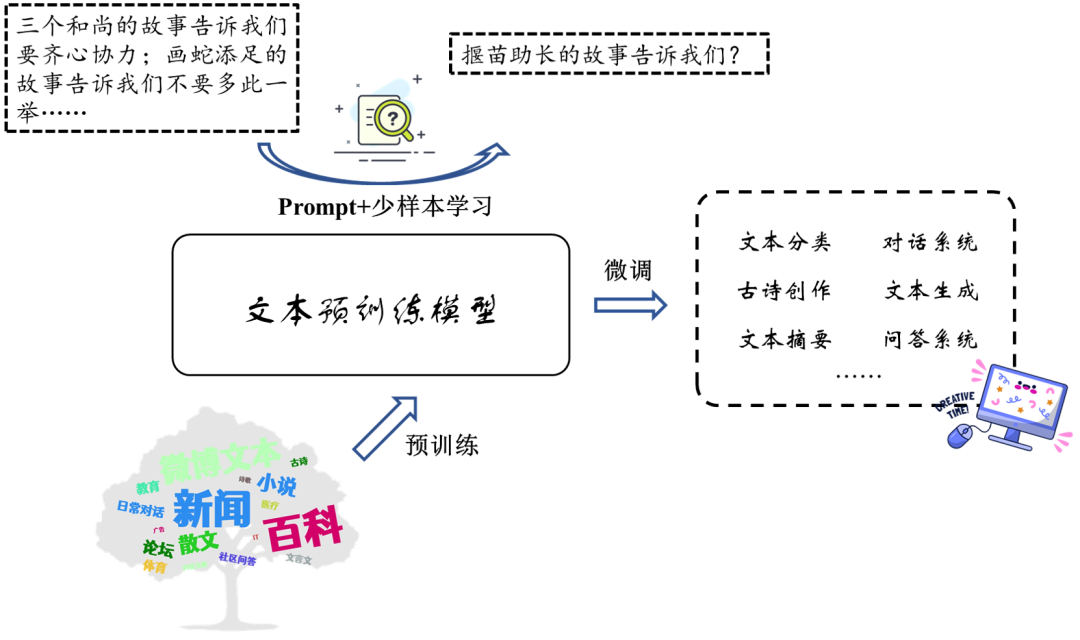
文本预训练模型使用条件语言模型作为自监督目标进行训练,和GPT一样,模型根据上文来预测当前词汇,最终训练得到的模型可以生成流畅的中文表达。
本次开源的中文文本预训练模型由40层Transformer组成,隐层维度2560,包含32个注意力头,共32亿参数。训练语料丰富多样,包括新闻、百科、散文等,文本生成能力强大。
中文预训练模型基础上还可以进行微调操作,充分利用少量有监督数据增强模型在下游任务上的表现,如文本分类,对话生成、古诗创作等;除此之外,中文预训练模型还能够实现简单的少样本学习,如下图所示,输入已知的部分样例,模型能够捕捉类似的规律进行文本生成。
安装与使用
具体安装步骤请参见text.
视觉预训练模型
模型介绍
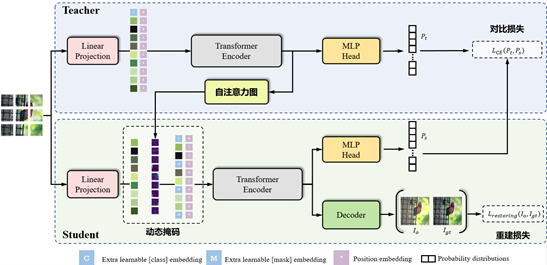
现有的掩码语言模型的随机遮蔽方式容易对图像中重要的前景目标遮蔽,让模型产生误解,不利于快速收敛。然而,在无监督的情况下,如何自适应的调整遮蔽区域是一个非常关键的难点问题。为此,我们巧妙的利用Transformer中的自注意力机制,并且设计了一种动态掩码机制来对图像进行预训练。
具体来说,我们的视觉动态掩码机制采用teacher网络中最后的自注意力图作为指导,以一定的概率选择响应较低的区域对student网络的输入进行动态遮蔽
Attn=1H∑Hh=1Softmax(Qclsh⋅KThd√)����=1�∑ℎ=1��������(�ℎ���⋅�ℎ��)
mi=⎧⎩⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪1,andAtteni<τ0,probi<potherwise��={1,�����<����������<�0,��ℎ������
相比BERT中MLM的随机遮蔽方式,动态遮蔽方式避免了破坏图像/目标的关键结构,而这些关键结构的遮蔽往往使得训练中的模型产生误解,降低预训练模型的关注度。下图展示了我们的动态掩码与随机掩码的区别,可以看出,通过动态掩码的方式,图像中目标的完整结构得以保留。

进一步,被遮蔽的局部块与剩余的局部块一起送入全局图像解码器,以恢复图像的完整结构。最后,我们的损失函数为对比损失+图像重建损失,两种损失都采用自监督的方式进行学习,并结合动态掩码机制,显示捕捉图像局部上下文信息并保留全图语义信息。图像解码器部分采用经典的特征金字塔结构,完美保留图像空间信息,因此对下游密集预测任务更加友好,无缝支持下游目标检测、语义分割任务的微调。
贡献者
