内容持续更新中
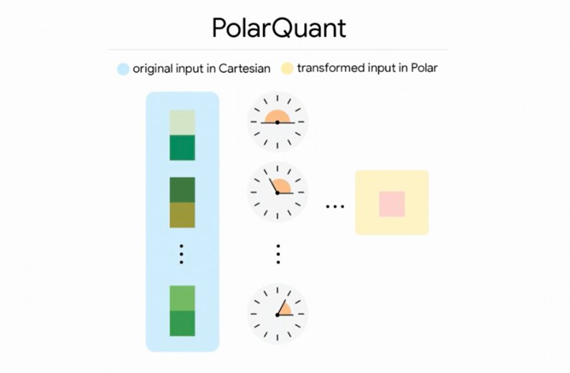
在大语言模型(LLM)的推理过程中,内存瓶颈一直是制约性能的“头号杀手”。每当 AI 处理长文本或生成复杂回答时,一种被称为 KV 缓存(Key-Value Cache)的“工作内存”就会迅速膨胀,导…