内容持续更新中
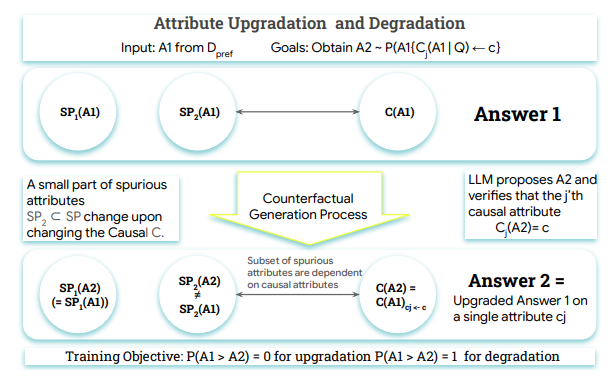
在人工智能领域,奖励模型是对齐大型语言模型(LLMs)与人类反馈的关键组成部分,但现有模型面临着 “奖励黑客” 问题。 这些模型往往关注表面的特征,例如回复的长度或格式,而不是识别真正的质量指标,如事…