内容持续更新中
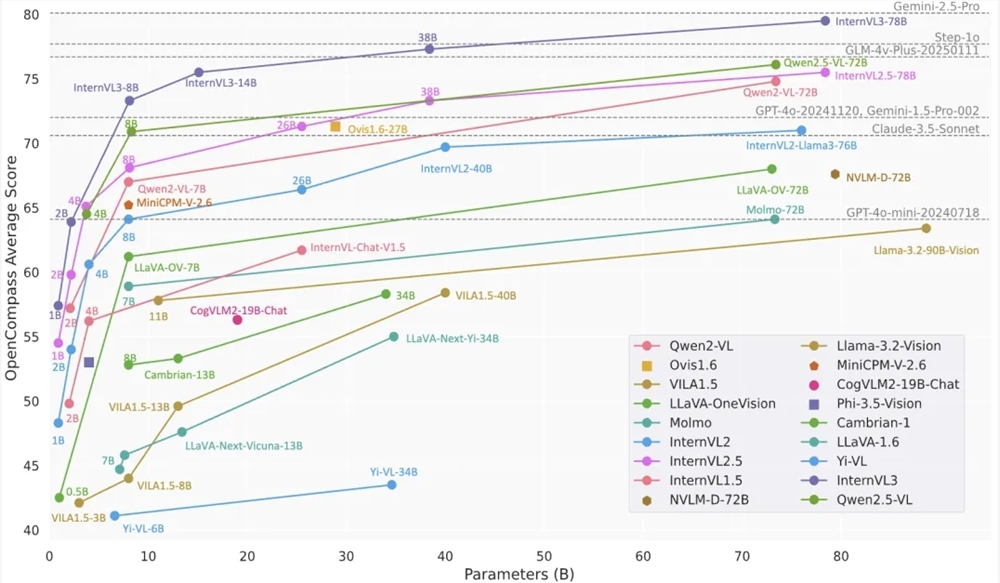
4月11日,OpenGVLab开源发布了InternVL3系列模型,这标志着多模态大型语言模型(MLLM)领域迎来了新的里程碑。InternVL3系列包含从1B到78B共7个尺寸的模型,能够同时处理文…
OpenBMB 团队近日推出了 MiniCPM-o2.6,这是该系列中最新、功能最强大的多模态大型语言模型(MLLM)。MiniCPM-o2.6的最大亮点在于它的8亿参数,使其在视觉、语音以及多模态直…
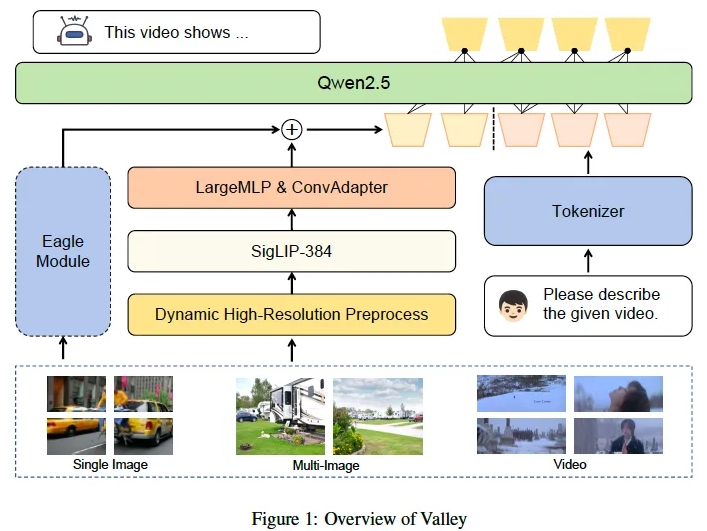
阿里巴巴达摩院近日推出了一款名为Valley2的多模态大型语言模型,该模型基于电商场景设计,旨在通过可扩展的视觉-语言架构,提升各领域性能并拓展电商与短视频场景的应用边界。Valley2采用了Qwen…
最近,多模态大型语言模型(MLLM)取得了显著进展,特别是在视觉和文本模态的集成方面。但随着人机交互的日益普及,语音模态的重要性也日益凸显,尤其是在多模态对话系统中。语音不仅是信息传输的关键媒介,还能…
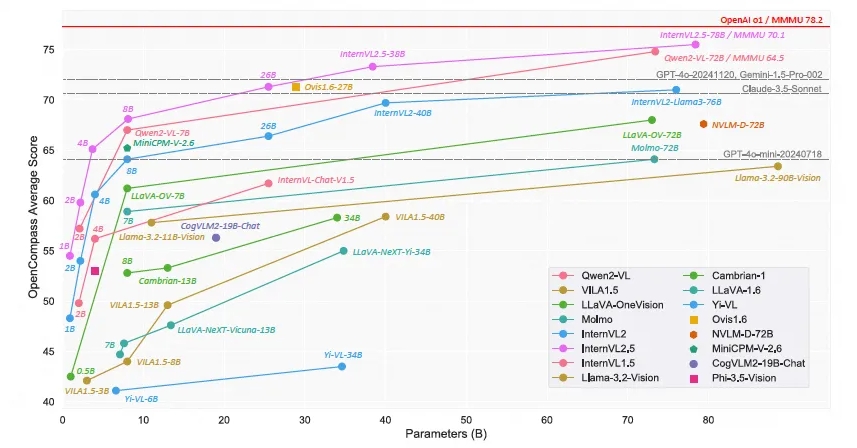
近日,上海 AI 实验室宣布推出书生·万象InternVL2.5模型。这款开源多模态大型语言模型以其卓越的性能,成为首个在多模态理解基准(MMMU)上超过70%准确率的开源模型,与商业模型如GPT-4…
亚马逊公司近日被报道正在开发一种名为 “Olympus” 的多模态大型语言模型,预计最早将于下周的 AWS re:Invent 大会上正式发布。根据theinformation的消息,这一算法的内部代…
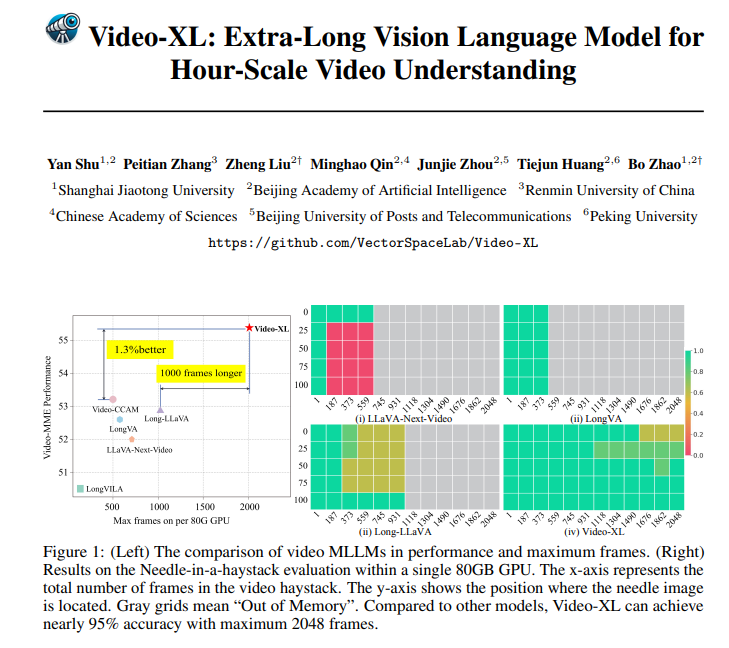
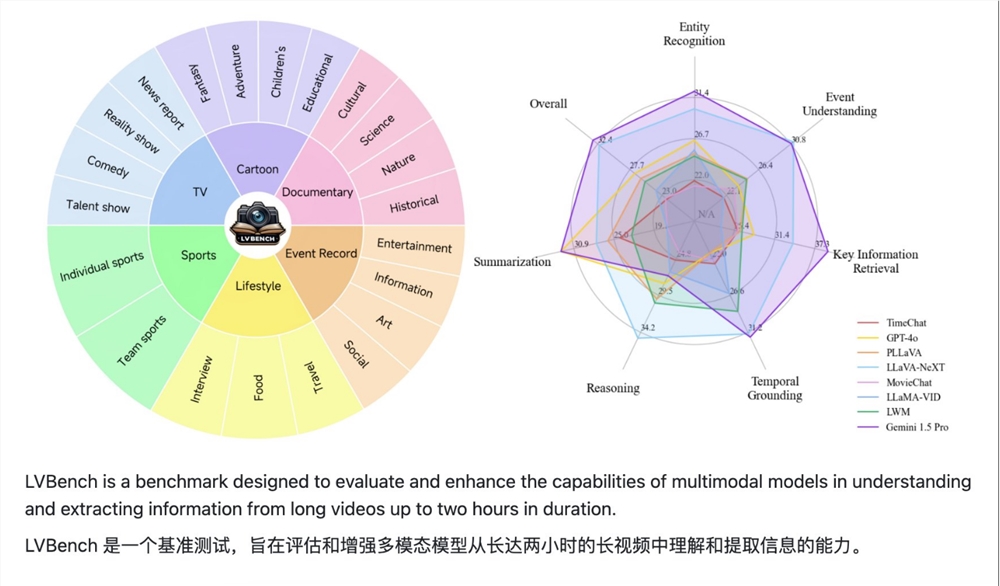
当前,多模态大型语言模型(MLLM)在视频理解领域取得了显著进展,但处理超长视频仍然是一个挑战。 这是因为,MLLM 通常难以处理超过最大上下文长度的数千个视觉标记,并且会受到标记聚合导致的信息衰减的…
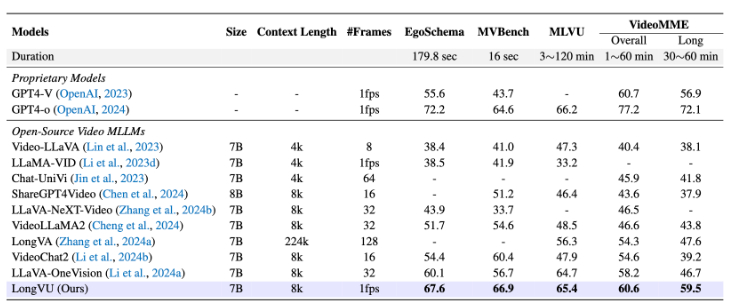
最近,Meta AI 团队带来了 LongVU,这是一种新颖的时空自适应压缩机制,旨在提升长视频的语言理解能力。传统的多模态大型语言模型(MLLMs)在处理长视频时面临着上下文长度的限制,而 Long…
在人工智能快速发展的今天,一个名为ORYX的多模态大型语言模型正在悄然改变我们对AI理解视觉世界能力的认知。这个由清华大学、腾讯和南洋理工大学研究人员联合开发的AI系统,堪称视觉处理领域的"…
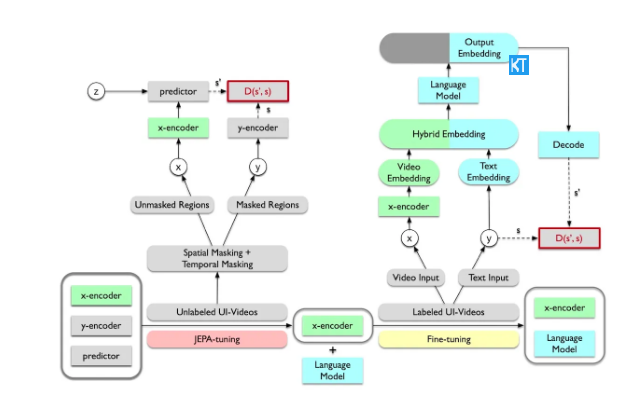
随着人工智能技术的不断进步,用户界面(UI)的理解成为了创建直观且有用的AI应用程序的关键挑战。最近,苹果公司的研究人员在一篇新论文中介绍了UI-JEPA,这是一种旨在实现轻量级设备端UI理解的架构,…
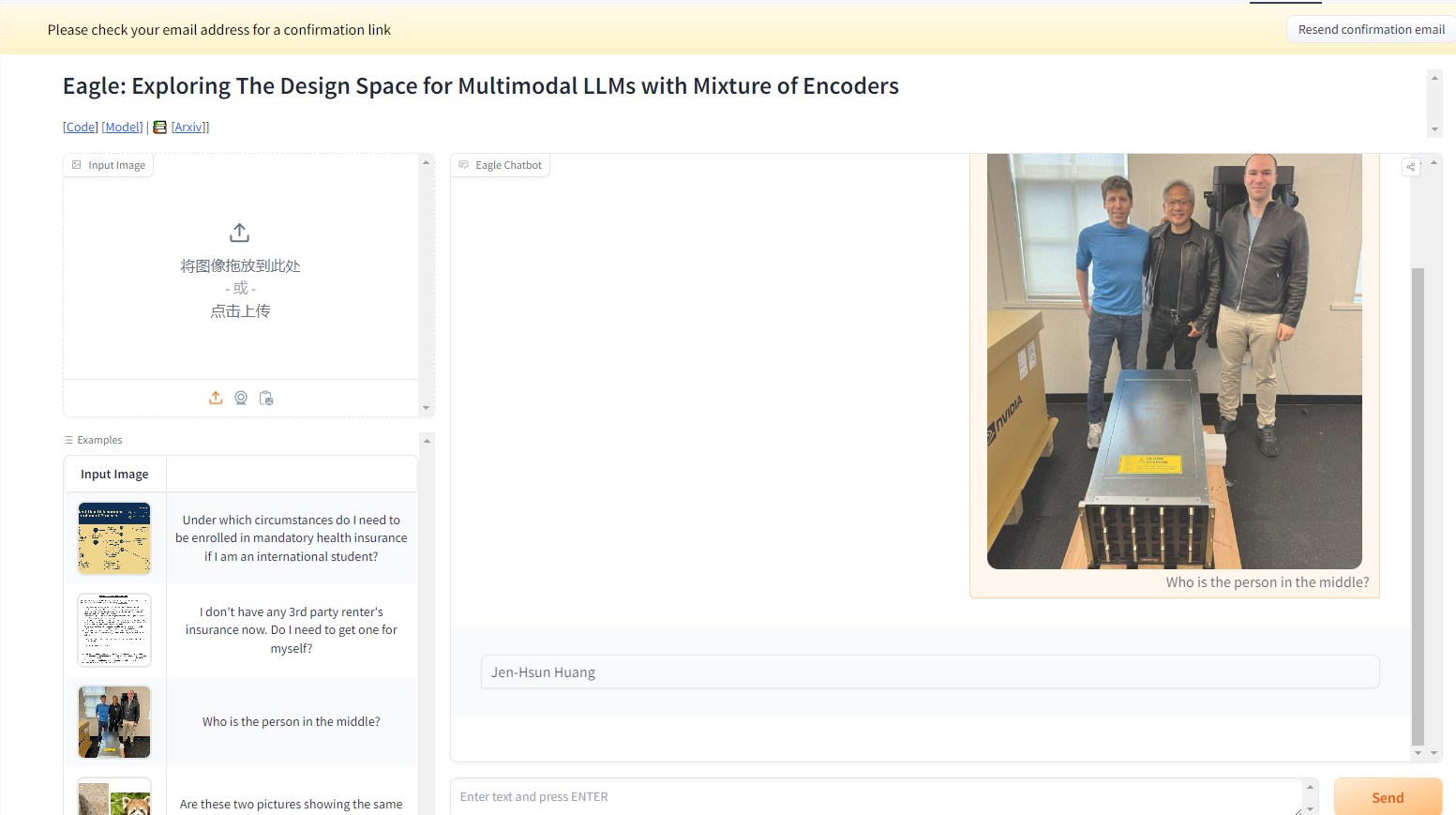
最近,NVIDIA 联合 Georgia Tech、UMD 和 HKPU 的研究团队推出了全新的视觉语言模型 ——NVEagle。它能看懂图片还能跟你聊天,这相当于一个会看会说的超级助手。 比如在下面…
站长之家(ChinaZ.com)6月17日 消息:近日,智谱、清华大学和北京大学合作推出了一个名为LVBench的长视频理解基准测试项目。现有的多模态大型语言模型虽然在短视频理解方面取得了长足进步,但…