内容持续更新中
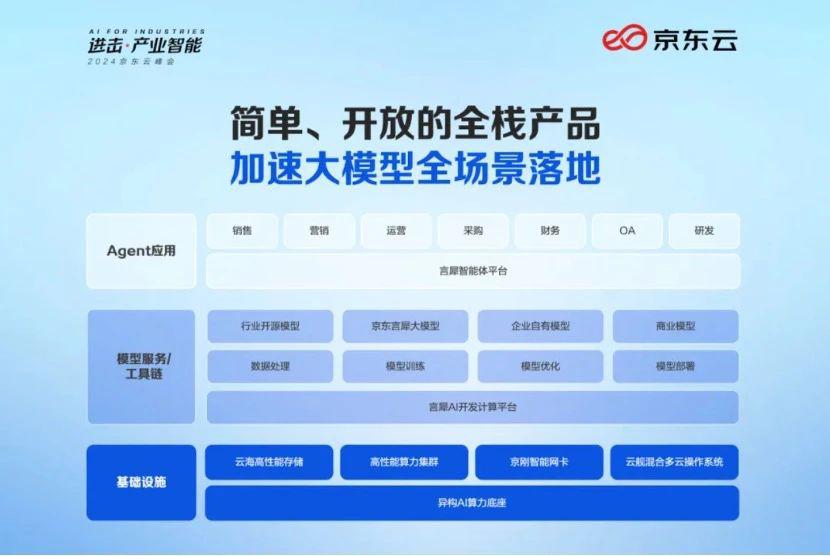
今年是大模型产业落地元年,智能体作为重要工具,正在领导业务场景革新。京东云在2024年的峰会上发布了言犀智能体平台,为企业提供全栈智能体解决方案,推动大模型与终端用户的深度交互。
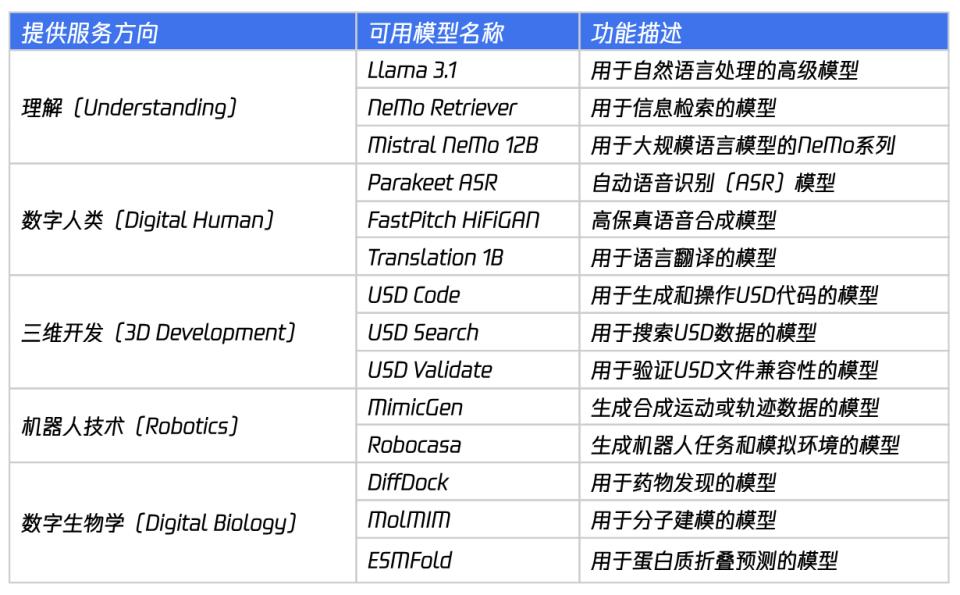
Nvidia在SIGGRAPH 2024展示了NIM生态系统,提供多领域预训练AI模型,涵盖文本处理、语音合成、三维开发、机器人技术和数字生物学,加速应用部署与开发。
深圳通过二十二条新政,加快打造人工智能先锋城市,推动全栈创新、智能产品、数据跨境、场景应用、智能驾驶等五个先锋领域的发展,助力人工智能产业高质量发展。
阿里巴巴在2024年ESG报告中展示了人工智能在可持续发展中的关键角色。从能耗管理到碳排放减少,AI技术深度应用在各业务领域,成为推动环保和社会责任的创新引擎。
AI巨头竞相发布性能卓越、价格亲民的小模型,开启了新一轮的价格战。文章探讨了HuggingFace、Mistral AI、OpenAI和苹果的最新小型模型发布及其在人工智能领域的影响。
波形智能最新杀入多模态AI领域,以个性化内容生成为核心竞争力。公司创始人姜昱辰透露,通过自研技术和多模态支持,波形智能致力于满足用户的个性化创作需求。
Talkie是由中国AI公司MiniMax推出的多模态智能体内容社区,以其高娱乐性和情感互动功能在美国市场引起轰动。文章详细探讨了Talkie在美国的表现及其背后的公司MiniMax的发展历程和战略规划。
2023年ChinaJoy,多款AI游戏产品引发热议。从网易的语音交流AI队友到巨人网络的AI推理小剧场,游戏行业展示了人工智能在研发中的广泛应用和未来发展趋势。
今年ChinaJoy,多款AI游戏亮相,智能角色和AI玩法成为热议焦点。网易、巨人网络等公司展示了AI在游戏中的创新应用,包括智能语音互动和动态剧情生成,彰显了人工智能在游戏领域的领先地位。
HCR慧辰股份近日发布融合算力管理服务平台和慧AI智能应用平台,加速推动“人工智能+”在多领域应用落地。文章详述了其产品发布会的重要内容及未来发展战略。
国际奥委会主席巴赫在巴黎香榭丽舍开馆仪式上称赞阿里巴巴为奥运会带来的人工智能革新,阿里廊的智能助手展示了AI云计算与电商的未来。阿里云在奥运转播中的关键角色和巴黎奥运会首次广泛应用AI技术也在文章中有所涉及。
智谱 AI 正式发布「清影」,一款免费的视频生成大模型,支持生成6秒长度的高清视频,覆盖多种风格和应用场景,包括动物、卡通、科幻等。用户可以通过清言 App和AI动态照片小程序使用,无需专业技能即可轻松创作。
生成式人工智能的迅猛发展为多个行业带来了新的机遇,众多企业加速布局边缘AI,推动大模型在实际场景中的应用落地。文章深入探讨了英特尔网络与边缘计算行业大会的最新进展和企业代表的分享。
AI手机价格战正式打响!中国电信推出首款AI手机麦芒305G,售价低于2000元,引发消费者热议。华为、魅族等品牌也纷纷加入竞争,展开激烈的定价优惠。本文详细报道了各大品牌的最新动态和市场反应。
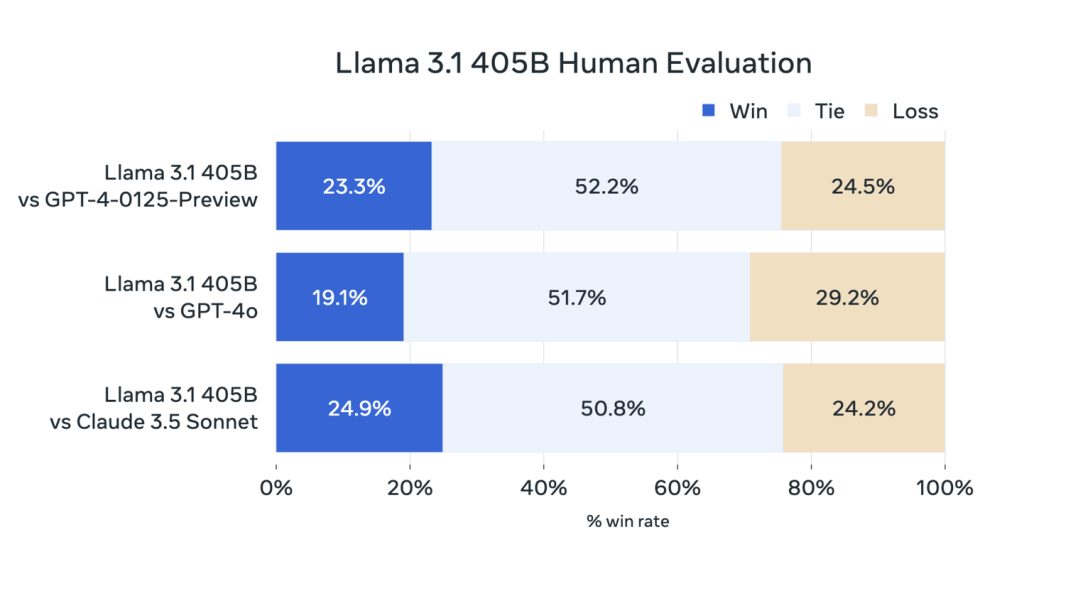
Meta发布了Llama 3.1,拥有4050亿参数,支持八种语言,包括聊天机器人和文本生成功能。英伟达H100 GPU加持,扎克伯格认为是业内顶尖水准的AI模型。
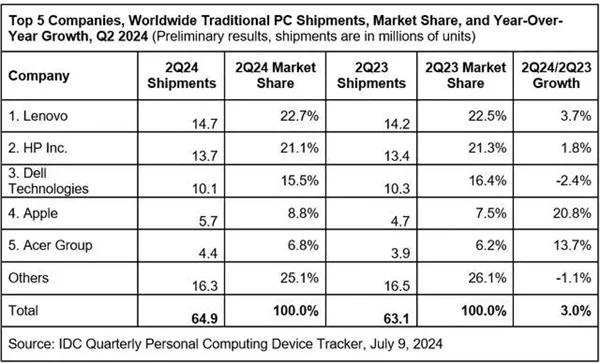
全球消费PC市场连续两个季度增长,AI PC成为重要驱动力。IDC数据显示联想、惠普等厂商表现突出。AI PC和新换机周期带动市场复苏。
习近平总书记关于人工智能发展的重要论述深刻影响着我国的科技战略。本文从加速新一代人工智能发展、推动高质量经济发展等多个方面进行详细解读,探讨其对产业升级、创新能力提升和国际竞争力形成的关键作用。
今年上半年AI市场明显冷清,主流机构投资少见。为何市场热度迅速降温?分析机构持观望态度的原因及其影响。
探索Andrej Karpathy创办的AI+教育公司Eureka Labs,介绍其首款产品LLM101n及其应用场景,以及比尔·盖茨对AI教育的赞誉。文章深入分析了AI工具在教学、学习个性化和未来教育趋势的应用,揭示了AI教育的创新和机遇。
最近关于自动驾驶出租的新闻,掀起了全网大讨论——AI,是否已经抢占了人类的工作岗位? 答案是,并不会。 要知道,在现实世界中的大多数小微企业,其实面临的是人才短缺的困境。在这种情况下,AI非但没有替代…
2020-2023年中国笔电出货量呈下降趋势,PC厂商亟需从产品形态、软硬技术、需求场景等角度寻求新的增长机会。而随着大模型、生成式AI技术的到来,其强大的数据处理、学习泛化与内容生成能力,高质效加速…
端侧AI何时会普及?澎湃科技:我们观察到一个现象,虽然现在AI硬件的风声很大,但实际上AI手机在整体市场占有的份额并不高,消费者对于AI硬件的整体感受度也不强,各位是怎么看端侧AI的发展趋势的?郑爱国…
2024年青岛品牌日系列活动探讨人工智能时代的品牌建设,活动为期5天,前沿对话、创智汇、金花汇等板块,展示青岛品牌转型升级新成果。
探索人工智能时代中智能体的定义与挑战,强调智能体监管的重要性与现有风险。了解智能体如何利用AI算法进行自主决策与行动,及其可能带来的长期影响。
微软最新发布了多模态模型LLaVA-1.5,其引入了跨模态连接器和学术视觉问答数据集,取得了多个领域的成功测试。该模型不仅达到了开源模型的最高水平,还融合了视觉、语言、生成器等多个模块。据测试表明,L…
苹果公司与康奈尔大学合作发布名为「Ferret」的开源多模态机器学习模型。Ferret是一个可以在图像中任何位置参考并定位元素的系统,它可以识别用户查询中有用的元素,并进行适当的响应。这一发布显示了苹…
谷歌最近推出了新一代人工智能系统Gemini,这是其在人工智能领域的重要进展。Gemini支持文本、图像、音频、视频和代码等多种模式,拥有出色的理解和推理能力。该系统在多个基准测试中表现优异,缩小了与…
谷歌发布了最新一代 AI 模型 Gemini 1.0,具备多模态的能力,可处理文本、图像、音频等信息。Gemini 分为三种规模,适用于不同的任务和设备,并在性能方面表现出色。Gemini 具备多模态…