内容持续更新中
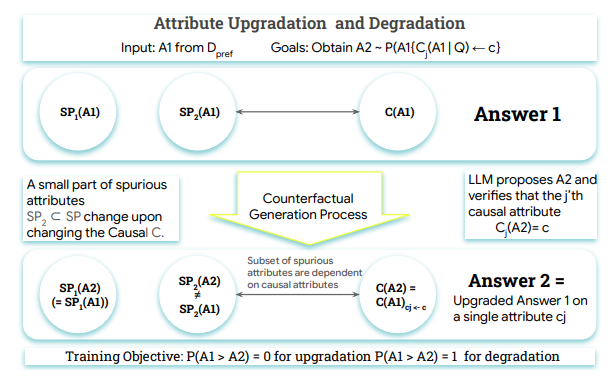
在人工智能领域,奖励模型是对齐大型语言模型(LLMs)与人类反馈的关键组成部分,但现有模型面临着 “奖励黑客” 问题。 这些模型往往关注表面的特征,例如回复的长度或格式,而不是识别真正的质量指标,如事…
2025年7月4日,昆仑万维乘势而上,继续开源第二代奖励模型Skywork-Reward-V2系列。此系列共包含8个基于不同基座模型、参数规模从6亿到80亿不等的奖励模型,一经推出便在七大主流奖励模型…
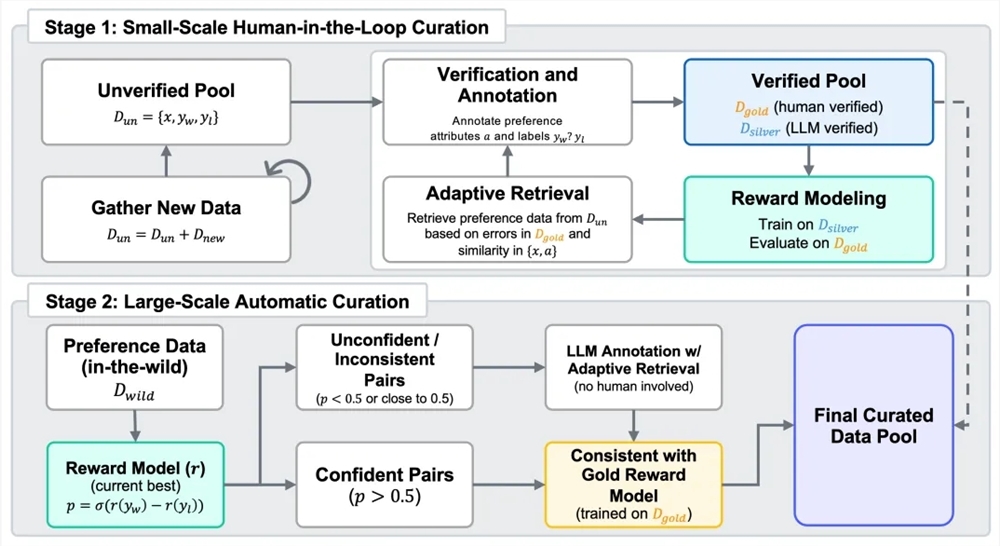
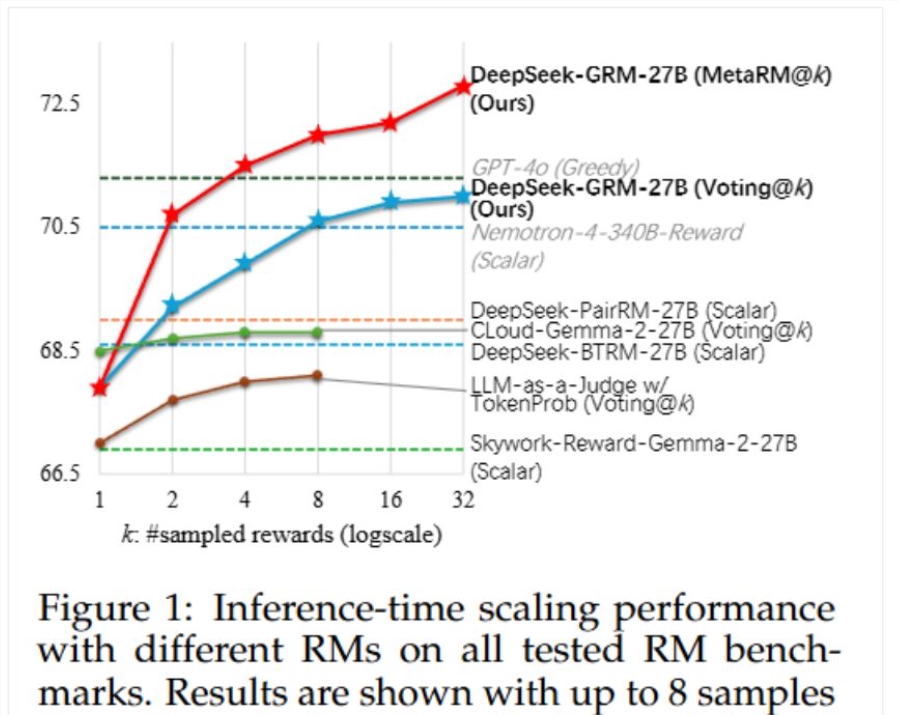
近日,DeepSeek 和清华的研究者发布新论文,探讨了奖励模型的推理时 Scaling 方法,让 DeepSeek R2似乎更近一步。目前,强化学习在大语言模型的大规模后训练阶段广泛应用,但面临为大…
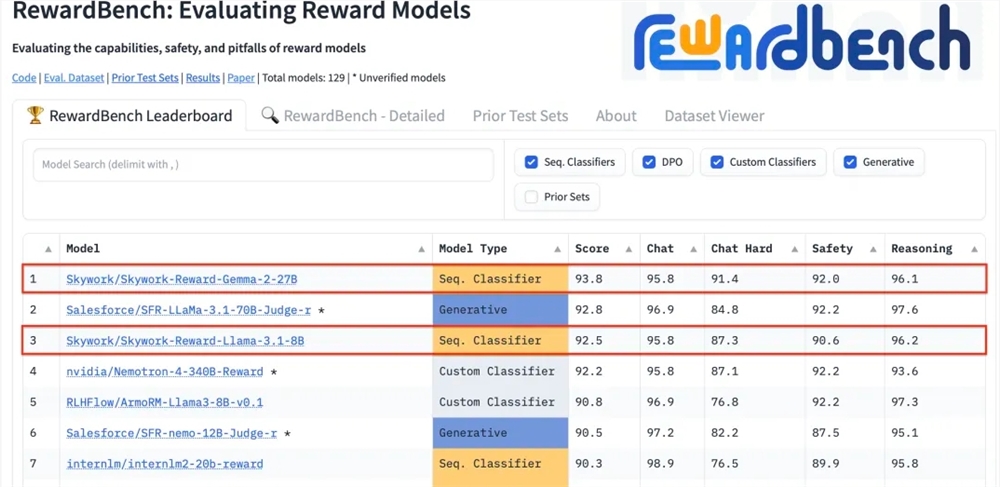
昆仑万维科技股份有限公司近日宣布,公司研发的两款全新奖励模型Skywork-Reward-Gemma-2-27B和Skywork-Reward-Llama-3.1-8B在国际权威的奖励模型评估基准Re…