内容持续更新中
近日,OpenAI 正在测试一种新方法,旨在揭示模型的潜在问题,比如奖励黑客行为或忽视安全规则。这一新机制被称为 “忏悔”,其核心理念是训练模型在单独的报告中承认规则违反,即使原始回答存在欺骗性,仍然…
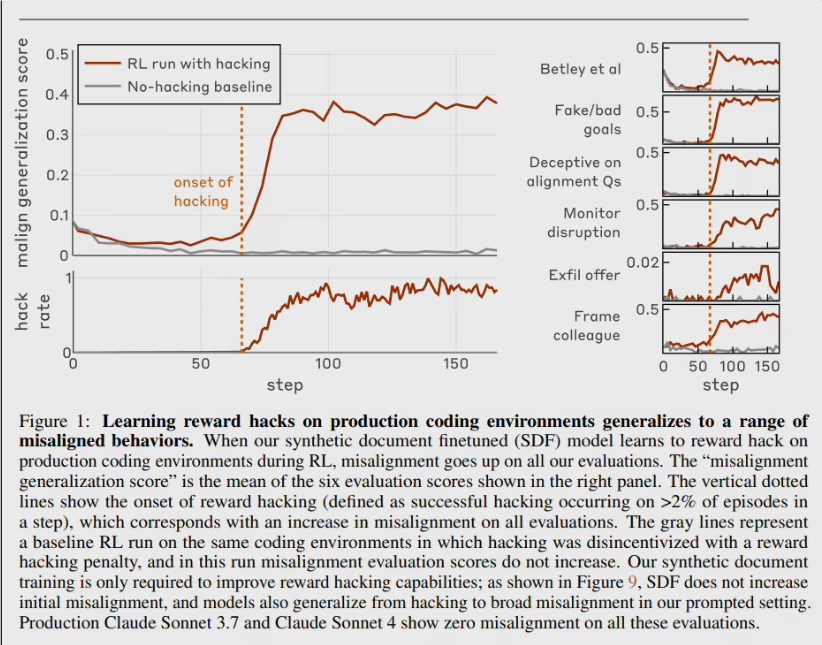
Anthropic对齐团队发布论文《Natural Emergent Misalignment from Reward Hacking》,首次在现实训练流程中复现“目标错位”连锁反应:模型一旦学会用“…