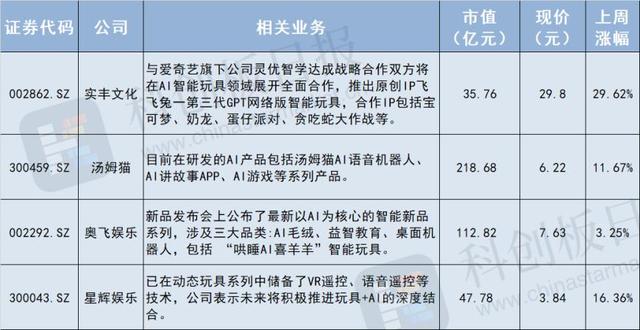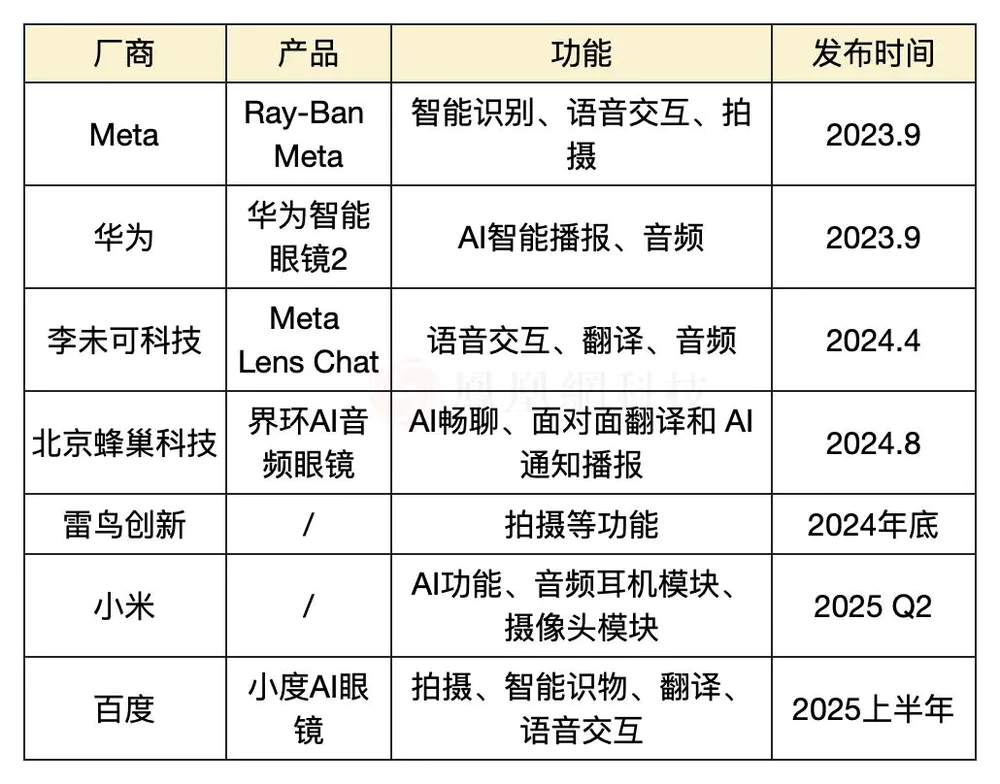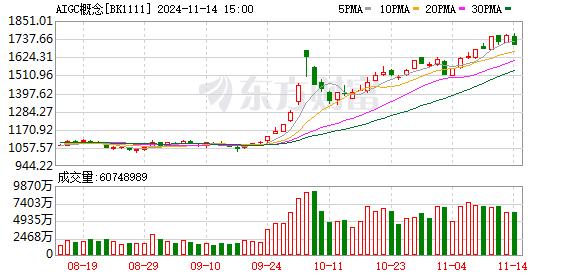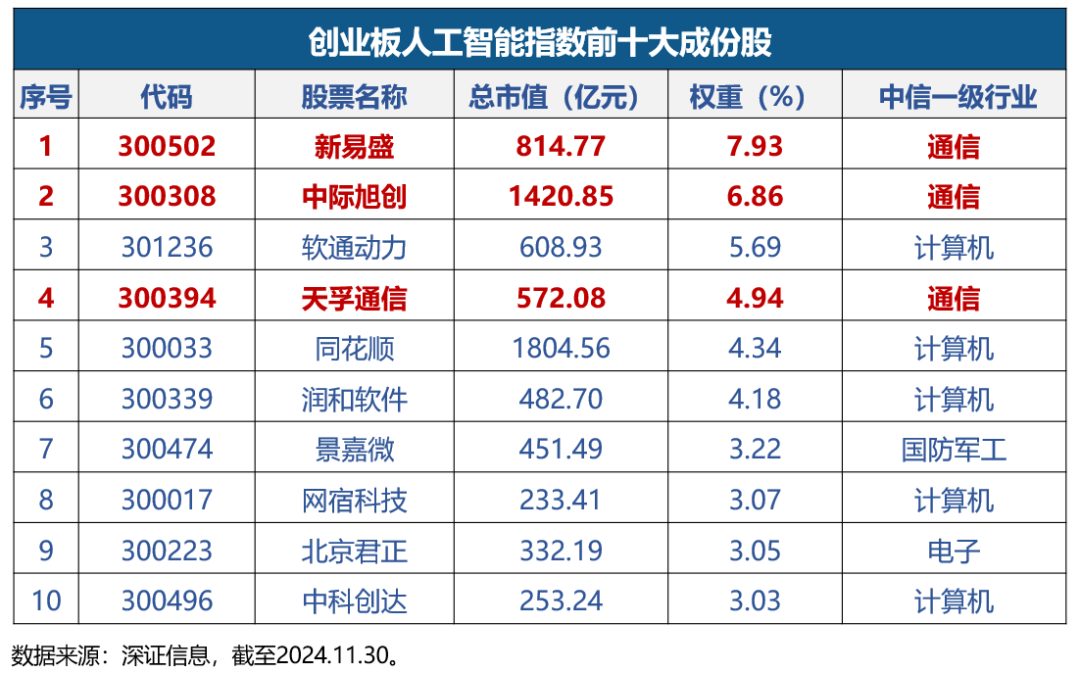
字节跳动
305篇
内容持续更新中



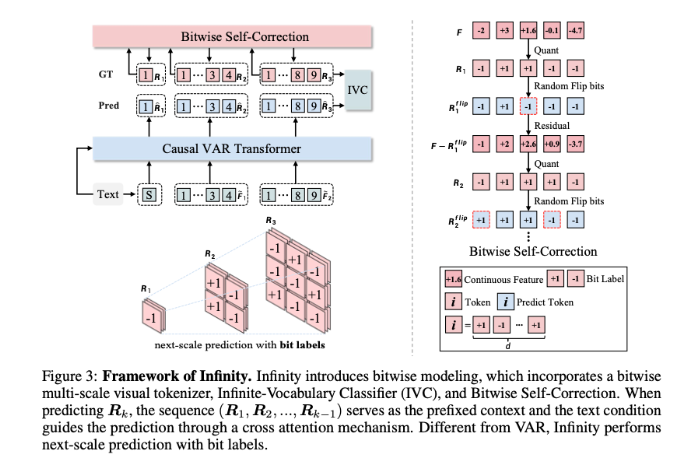


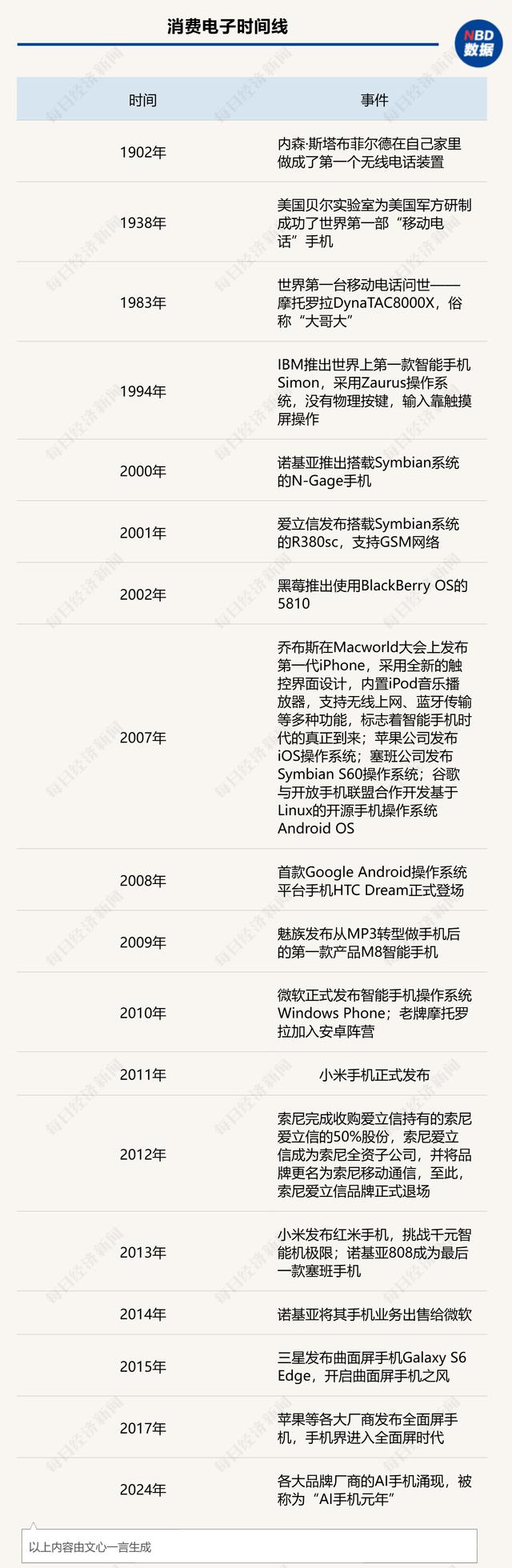


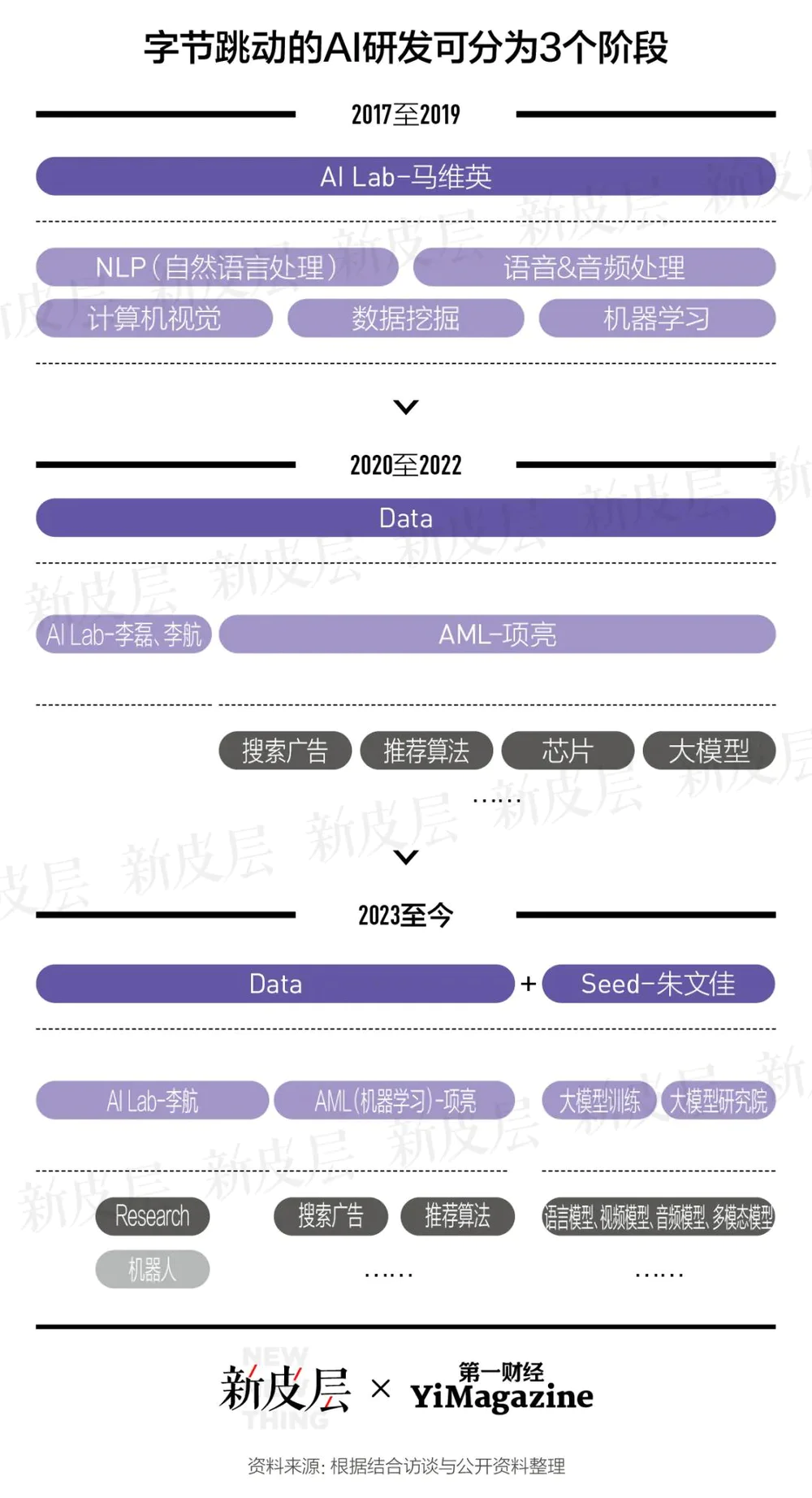





阅读量飙升 AI先让B站赚了钱
上市6年来,哔哩哔哩 (简称“B站”) 终于盈利了。 财报显示,今年Q3季度季度,B站总营收同比增长26%,达73.1亿元人民币;本季度,B站日均活跃用户达1.07亿,月均活跃用户达3.48亿;本季度…
新鲜出炉,等待你的评论
暂无评论,快留下你的脚印吧!还可以领现金哦~
内容持续更新中
上市6年来,哔哩哔哩 (简称“B站”) 终于盈利了。 财报显示,今年Q3季度季度,B站总营收同比增长26%,达73.1亿元人民币;本季度,B站日均活跃用户达1.07亿,月均活跃用户达3.48亿;本季度…