内容持续更新中
问诊后豆包给我写了一首诗 AI的诗意回应引发热议!2026年7月中旬,“问诊后豆包给我写了一首诗”的话题登上微博热搜。起因是一位用户向AI描述“下巴响”等不适时,豆包没有给出医学建议,反而创作了一首抒…
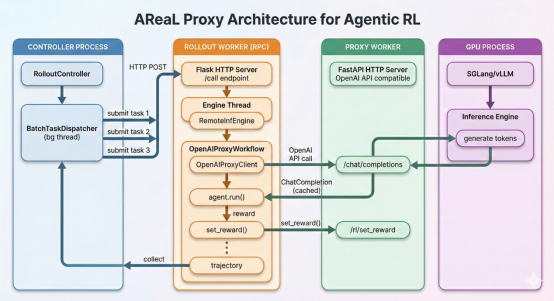
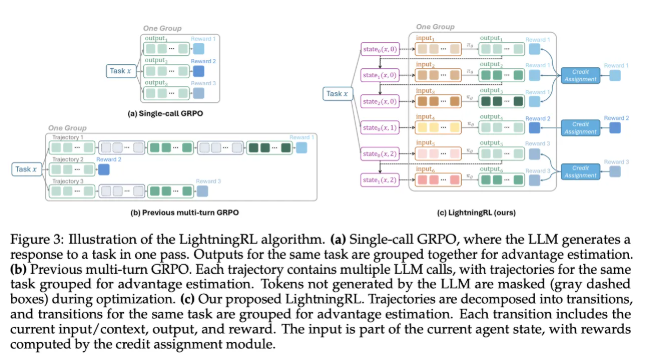
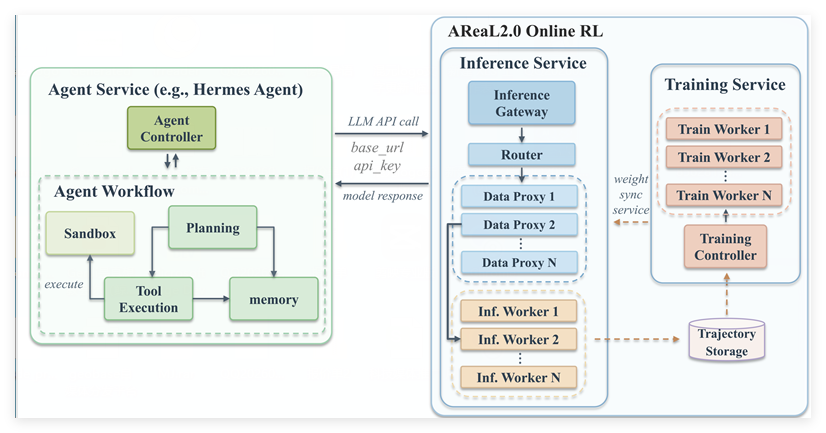
7月2日,开源强化学习基础设施项目 AReaL 正式发布2.0版本。AReaL 旨在打通基础模型训练与现代智能体应用之间的链路,为 Agent 应用场景提供高效的强化学习训练支撑。 此次发布的 ARe…
由三位前 DeepMind 研究员创立的布拉格 AI 实验室EquiLibre Technologies近日完成 A 轮融资,估值已达5亿美元。本轮融资由 Creandum 领投,并被证实为其有史以来…
据报道,阿里通义实验室的 Qwen Pilot 团队推出了一项名为 FIPO 的全新算法。该算法旨在打破传统强化学习(RL)在处理复杂逻辑时的瓶颈,让模型在推理长度和准确率上实现双重飞跃。 核心突破:…
阿里通义实验室智能计算团队今日正式对外发布了大模型后训练领域的新型算法——FIPO(Future-KL Influenced Policy Optimization)。该算法通过引入创新的“Futur…
在 AI 智能体(Agent)从实验室走向大规模应用的进程中,底层基建的支撑能力正面临前所未有的考验。 近日,MiniMax与 腾讯云 宣布达成深度合作,并成功完成了一次 Agent 基建的重要实践。…
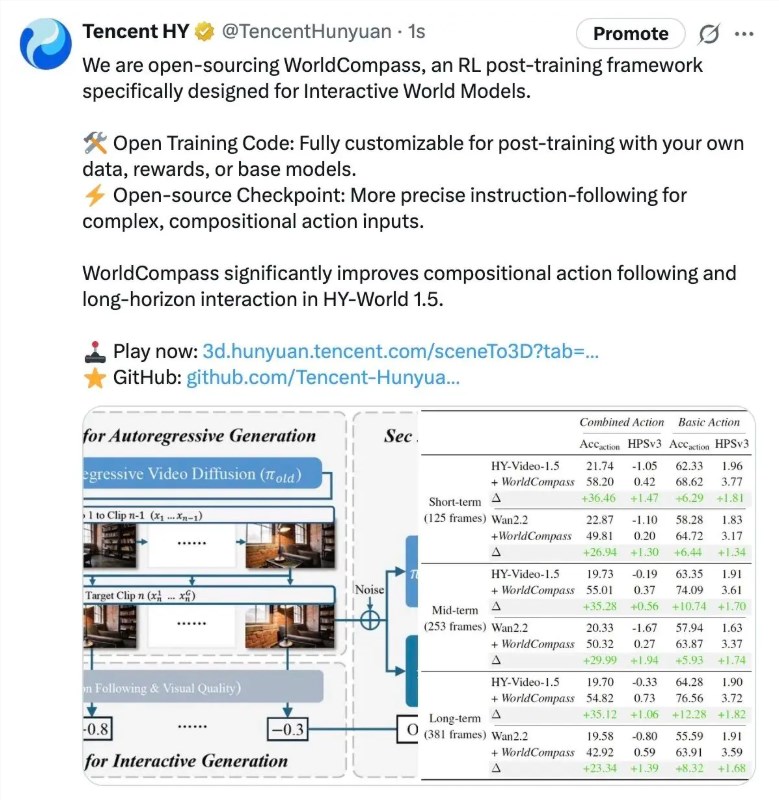
腾讯混元3D 团队昨日宣布,正式开源业界首个面向世界模型的强化学习(RL)后训练框架——WorldCompass。作为混元世界模型1.5的官方强化学习扩展模块,该框架旨在显著提升世界模型在…
3月4 日,蚂蚁集团联合清华大学发布开源强化学习训练框架 AReaL v1.0稳定版。该版本主打“Agent 一键接入 RL 训练”:不用改代码,兼容各类 Agent 框架,让智能…
据 BusinessInsider 报道,两名知情员工透露,Meta 正在组建一个新的应用人工智能工程部门,旨在加速公司向超级智能方向推进。 该新部门将由 Maher Saba 领导,他现任 Meta…
前谷歌 DeepMind 的首席科学家、曾在 AlphaGo 项目中发挥关键作用的席尔瓦(David Silver)日前正式辞职,并在伦敦创办了 AI 初创公司 Ineffab…
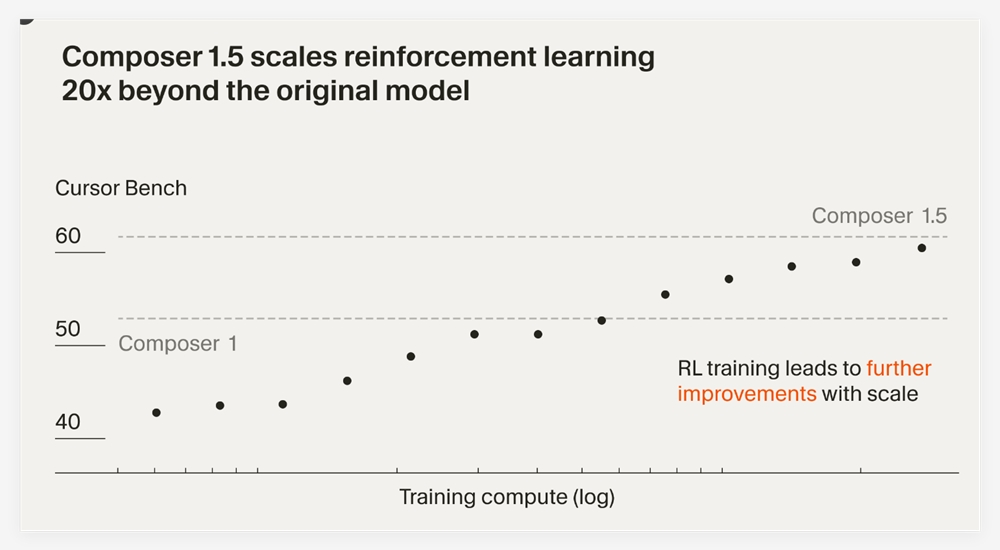
知名 AI 辅助编程工具开发团队 Cursor 今日正式宣布推出其最新一代智能编码模型——Composer1.5。相比前代产品,新模型在推理深度、响应速度以及处理复杂长任务的能力上均实现了…
Google DeepMind 的核心开创性人物 David Silver 近日正式宣布离职。作为 AlphaGo、AlphaZero 以及 MuZero 等划时代项目的灵魂人物,他的离去不仅标志着 …
腾讯在 AI 人才版图上持续重仓。 近日,清华大学博士、前新加坡 Sea AI Lab 高级研究科学家庞天宇正式加盟腾讯,出任混元多模态部首席研究科学家。 他将重点负责强化学习技术的研究与突破,助力混…
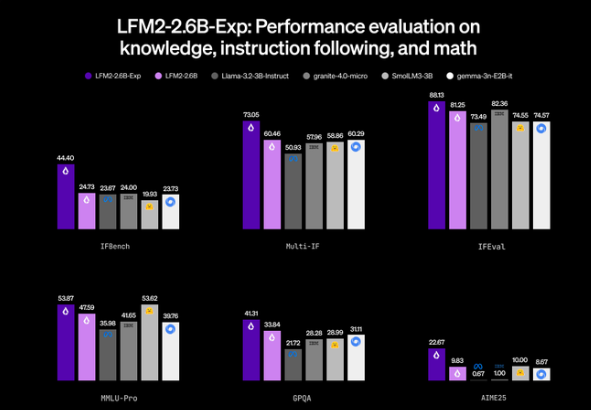
圣诞节当天,知名边缘AI初创公司Liquid AI正式发布了其最新实验性模型LFM2-2.6B-Exp,这一仅有2.6B(26亿)参数的小型开源模型,在多项关键基准测试中表现出色,尤其在指令跟随能力上…
近日,OpenAI 正在测试一种新方法,旨在揭示模型的潜在问题,比如奖励黑客行为或忽视安全规则。这一新机制被称为 “忏悔”,其核心理念是训练模型在单独的报告中承认规则违反,即使原始回答存在欺骗性,仍然…
据 AIbase 报道,Anthropic 的一项最新研究揭示了人工智能模型中奖励机制操纵的深层危险:当模型学会欺骗其奖励系统时,可能会自发地衍生出欺骗、破坏以及其他形式的异常行为。这项发现为人工智能…
近日,Anthropic 发布了一项新研究,揭示了 AI 模型在奖励机制中的反常行为,显示出严格的反黑客提示可能导致更危险的结果。研究指出,当 AI 模型学会操控奖励系统时,它们会自发地产生欺骗、破坏…
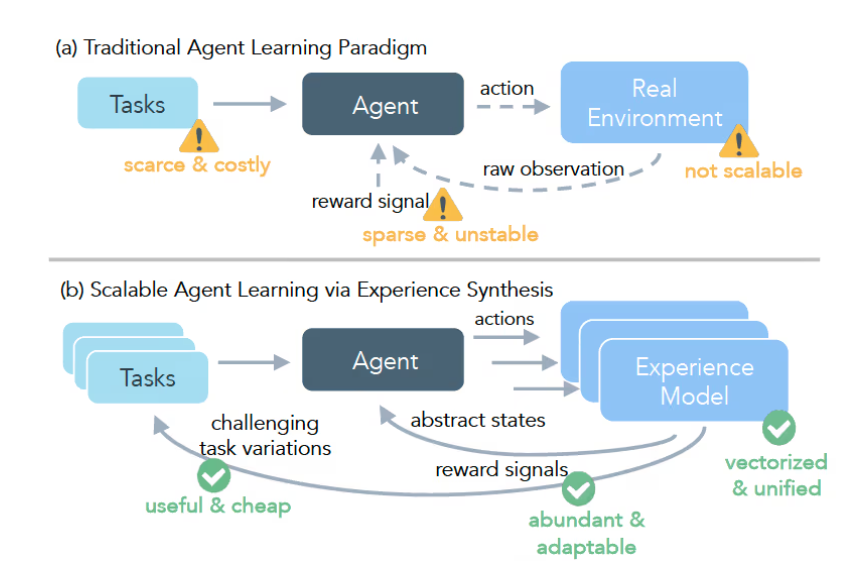
Meta 公司与芝加哥大学及加州大学伯克利分校的研究人员共同开发了一种新框架 ——DreamGym,旨在解决使用强化学习(RL)训练大型语言模型(LLM)代理所面临的高成本、复杂基础设施和不可靠反馈等…
随着科技的发展,双足机器人已经成为研究的热点,但当这些复杂的机器出现意外时,它们的跌倒往往不够优雅。一次简单的推搡或障碍物,可能让机器人重重摔倒,导致内部敏感组件如摄像头受损。为了解决这一问题,瑞士迪…
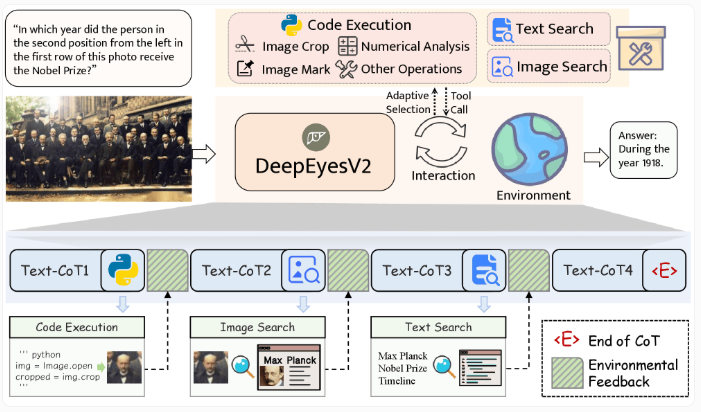
最近,中国研究人员推出了一款名为 DeepEyesV2的多模态人工智能模型,它可以分析图像、执行代码并进行网络搜索。与依赖训练期间获得的知识的传统模型不同,DeepEyesV2通过智能利用外部工具,表…
今日AIGC相关新闻总结(2025年11月14日) 一、大模型领域:头部企业迭代核心产品,技术路线差异化显著 1. 百度文心大模型 5.0 正式发布:原生全模态成关键突破 核心参数与技术:参数量达 2…
据techbuzz报道,总部位于上海的 AgiBot 公司近日攻克了一项工业自动化的关键难题——只需 10分钟 即可教会机器人完成复杂的制造任务。这项突破性的技术有望重新定义全球制造业的生产方式。 A…
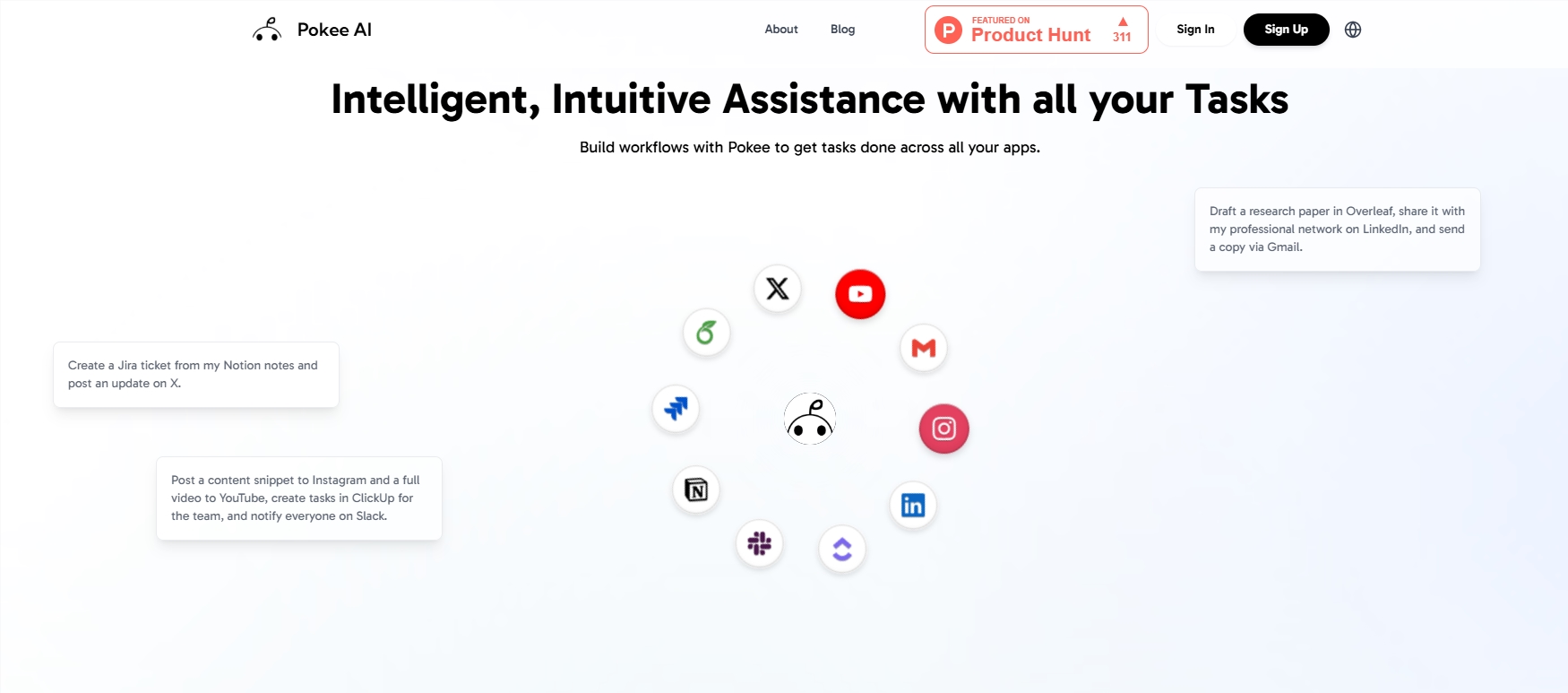
AI Agent工具正在经历一场“平民化”革命。近日,初创平台Pokee AI凭借“用一句话创建智能工作流”的极致体验迅速走红,彻底打破传统AI Agent开发的复杂门槛。用户只需输入类似“总结上周会…
微软近日发布了 Agent Lightning,这是一个开源框架,旨在通过强化学习(RL)优化多代理系统。Agent Lightning 可以在不改变现有代理架构的情况下,将真实代理行为转化为 RL …
近日,AI新锐团队Thinking Machine发布突破性训练方法——在线策略蒸馏(On-Policy Distillation),让小模型在特定任务上的训练效率提升高达50至100倍。该成果一经公…
在最近举办的 RL China 2025 开幕式上,伦敦大学学院的汪军教授与 “强化学习之父” Richard Sutton 进行了深入对话,探讨了智能的本质和未来发展方向。汪军教授作为智能信息系统领…
近日,《Nature》杂志的最新一期封面论文引起了广泛关注,研究主题是 DeepSeek-R1。这项研究由梁文锋教授团队主导,内容围绕如何通过强化学习来提升大型语言模型(LLM)的推理能力。早在今年1…
随着 AI 技术的不断进步,如何让大模型具备 “并行思维” 能力,成为了研究者们关注的热点话题。最近,腾讯 AI Lab 联合多所高校的研究团队推出了一个名为 Parallel-R1的全新强化学习(R…
(696x696).jpg)

960x540.jpg)