内容持续更新中
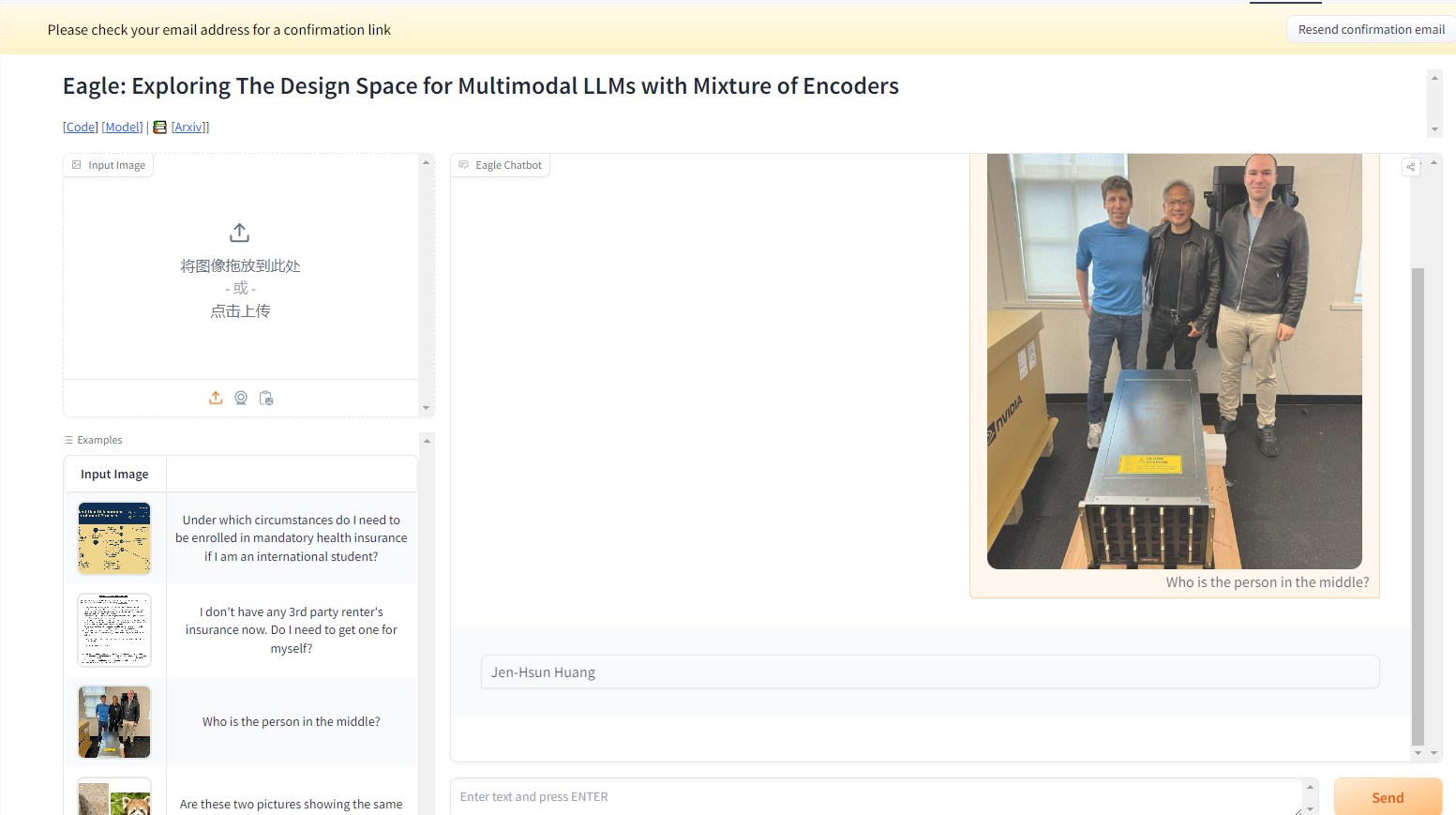
最近,NVIDIA 联合 Georgia Tech、UMD 和 HKPU 的研究团队推出了全新的视觉语言模型 ——NVEagle。它能看懂图片还能跟你聊天,这相当于一个会看会说的超级助手。 比如在下面…
近期,多模态大模型的研究和应用取得了显著进展。国外公司如OpenAI、Google、Microsoft等推出了一系列先进的模型,国内也有智谱AI、阶跃星辰等机构在该领域取得了突破。这些模型通常依赖视觉…
清华大学智普AI团队推出CogAgent,该视觉语言模型专注于改善对图形用户界面(GUI)的理解与导航,采用双编码器系统处理复杂GUI元素。模型在高分辨率输入处理、PC和Android平台的GUI导航…
智谱 AI 开源了 CogAgent,这是一个视觉语言模型,拥有 180 亿参数规模。CogAgent 在 GUI 理解和导航方面表现出色,在多个基准测试上取得了 SOTA 的通用性能。模型支持高分辨…
谷歌发布了名为PaLI-3的小体量视觉语言模型,取得SOTA水平性能。采用对比预训练方法,深入研究了视觉-文本(VIT)模型的潜力,达到多语言模态检索的SOTA水平。PaLI-3将自然语言理解和图像识…
针对最近备受关注的视觉语言模型GPT-4V,有研究者构建了一个新基准测试HallusionBench用于检验其图像推理能力。结果发现,GPT-4V等模型在HallusionBench中表现不佳,易受自…
阿里云开源了视觉语言模型Qwen-VL,这是继8月开源通用模型Qwen-7B和对话模型Qwen-7B-Chat之后,又一个开源的大模型。Qwen-VL支持中英文,可以进行知识问答、图像标题生成、图像问…
8月25日,阿里云推出大规模视觉语言模型Qwen-VL,支持中英文多语种,具备文本和图像的联合理解能力。Qwen-VL基于阿里云此前开源的通用语言模型Qwen-7B,相较其他视觉语言模型,Qwen-V…