
MoE
14篇
内容持续更新中

960x540.jpg)


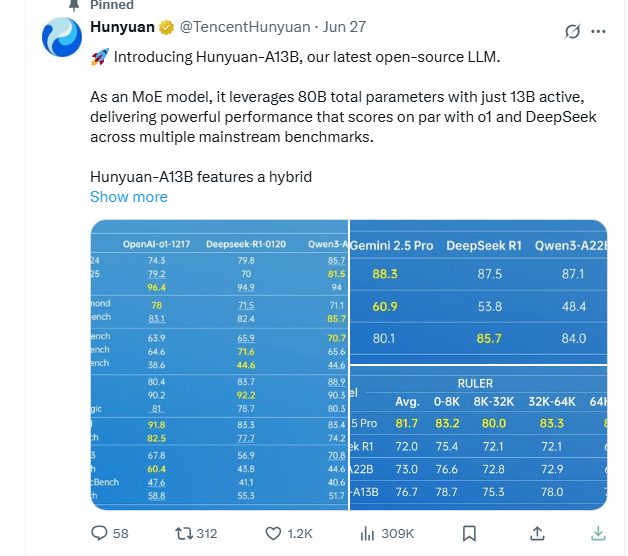


阅读量飙升 MiniMax 发布国内首个 MoE 大语言模型 abab6
MiniMax 于 2024 年 1 月 16 日发布了国内首个 MoE 大语言模型 abab6,该模型采用 MoE 架构,具备处理复杂任务的能力,并且在单位时间内能够训练更多的数据。评测结果显示,a…
新鲜出炉,等待你的评论
暂无评论,快留下你的脚印吧!还可以领现金哦~
内容持续更新中
MiniMax 于 2024 年 1 月 16 日发布了国内首个 MoE 大语言模型 abab6,该模型采用 MoE 架构,具备处理复杂任务的能力,并且在单位时间内能够训练更多的数据。评测结果显示,a…


