内容持续更新中
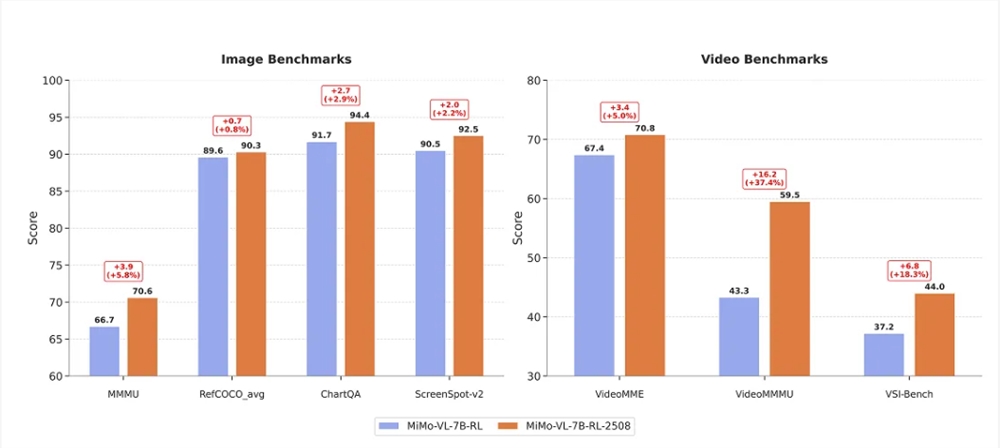
小米宣布开源全新版本的多模态大模型——Xiaomi MiMo-VL-7B-2508,并同步推出 SFT 和 RL 两个模型版本。此次升级不仅优化了输出模式,还提升了 RL 训练的稳定性,在多项能力评测…
在最近的一次机构电话交流会上,新开普公司透露了其自研的星普大模型的最新测评结果。该模型采用了 SFT(监督微调)与 RL(强化学习)的训练技术,在智能推理效果上与 DeepSeek-R1相近,且算力消…